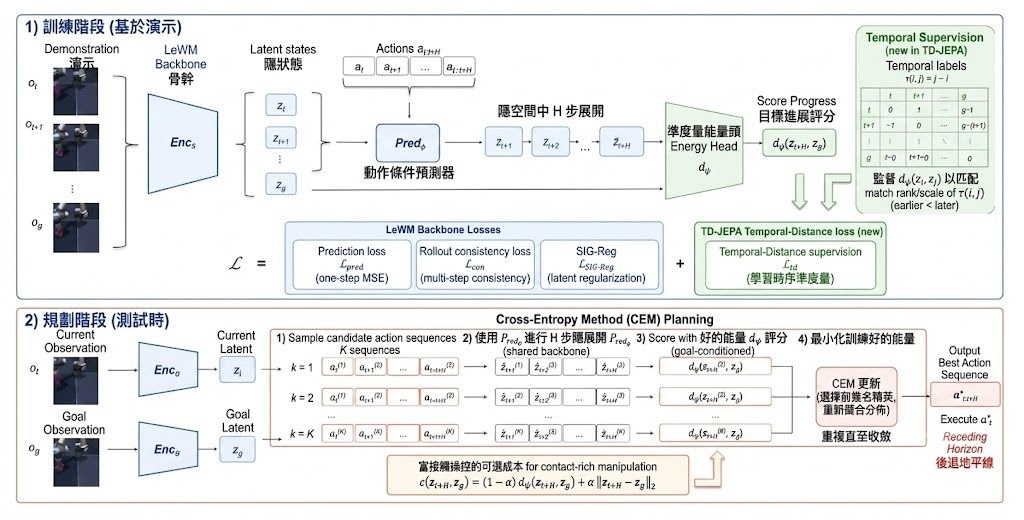
香港浸會大學 HKBU KnowComp 的 Jiaxin Bai 公開了 Temporal-Distance-JEPA 論文重現項目,核心不是再做一個更複雜的世界模型,而是修正 JEPA 規劃常見的落差:訓練時學短期 latent prediction,規劃時卻往往直接拿 latent Euclidean distance 當成目標進度。這個項目屬於模型研究重現項目,處理的是離線示範沒有 reward 時,planner 點樣判斷哪條想像路徑更接近目標。
作者保留 LeWM encoder–predictor 與 SIGReg backbone,但不再只依賴 embedding 幾何,而是從 reward-free demonstration logs 挖出 directed temporal cost。做法沿住論文邏輯很清楚:同一條 trajectory 的先後步序提供 positive targets,跨 trajectory 配對充當 heuristic negatives,再用 rollout-consistency 令學到的成本更貼近 planner horizon。這種 framing 直接回應舊範式把 latent L2 當成進度代理的限制,因為拓撲主導任務未必適合只看幾何距離。
結果在 Two-Room、Reacher 這類 topology-dominated tasks,規劃時直接部署 mined cost d_psi;到了 Push-T、OGB-Cube 這類 contact-rich tasks,則改用同一個 temporally trained checkpoint 上的 latent l2 planning。locked evaluation 下,Two-Room 成功率提升到 100.0%,高於 LeWM 的 97.4%;OGB-Cube 亦比 LeWM 高 14.2 分,並且整體上對 LeWM 與 RC-aux baseline 都能持平或更好。
- 建基於 stable-worldmodel、stable-pretraining 與 LeWM 既有布局,重點在訓練目標與規劃成本的重新對齊
- 公開庫是 paper-reproduction release,保留 Python CLI,但刻意不附 cluster/Slurm 包裝
- 資料以 HDF5 形式放在 STABLEWM_HOME,涵蓋 Push-T、Two-Room、Reacher、OGB-Cube
- 採用 10 epochs,並附有 locked results、cost matrix、diagnostics 等結果資料
這個庫比較像給已有研究工作流的人接手重跑:有 Python 環境、requirements、Hydra config、資料位置與 checkpoint 輸出方式,但沒有替不同排程系統準備現成封裝。歷史上的 contrastive SoftJEPA 相容程式仍可能留在 losses.py 或 jepa.py,不屬於公開配置;換句話說,閱讀與重現時要以 td_jepa 設定為準。對做 world model、offline RL、latent MPC 的研究團隊來說,這個項目最有價值的地方,是它把「表示學到什麼」與「規劃要怎樣排序未來」重新綁在一起。