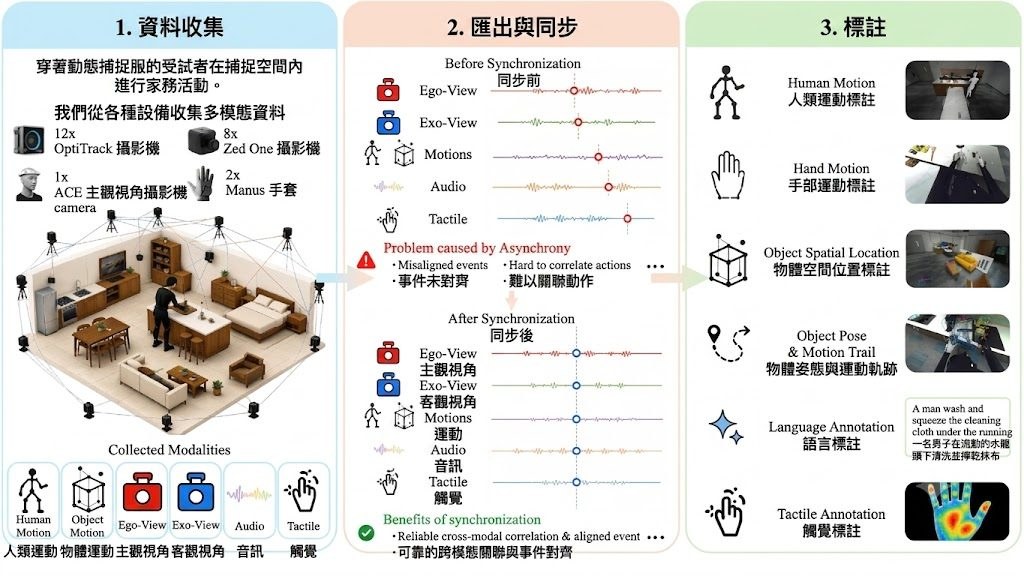
家居環境入面嘅長時間活動,一直係具身 AI 最難補足嘅數據缺口。ACE-Data-0 聚焦嘅唔係幾秒鐘嘅單一步驟,而係一段完整家務流程點樣一路影響視角、身體動作、物件狀態、接觸訊號同聲音,令模型可以學到「同一件事點樣隨時間演變」。
項目背後用 Ambient Capture Engine(ACE),將真實住宅場景變成同步錄製系統,並且同時覆蓋 table-scale 同 room-scale 兩個尺度。重點唔止係拍到第一身畫面或者外部鏡頭,而係將 ego view、exo views、body motion、hand articulation、object state、audio 同 touch 對齊到同一時間線,整理成可訓練、可標註嘅 embodied AI 數據。
相比只提供單一視角影片、實驗室動作捕捉,或者只得短片段互動記錄嘅常見做法,ACE-Data-0 更著重完整性同連續性。它以 household goal 為單位記錄活動,參與者自然完成任務,過程可以跨房間、牽涉多個物件,亦會保留場景由初始狀態、中途改變到任務完成嘅完整軌跡,較適合研究長程規劃、狀態追蹤同記憶能力。
- 用同步多模態方式記錄真實家居活動,而唔係只截取短動作片段
- 同一事件內對齊視角、身體、手部、物件、聲音同接觸訊號
- 以目標導向活動收集數據,保留跨步驟、跨房間嘅連續變化
- 適合具身 agents、機械人感知與操作、長時序決策相關研究
現有資料清楚交代咗項目定位、捕捉方式同數據價值,亦提到已釋出技術報告同 Hugging Face dataset。適合先將它理解為一個面向具身 AI 數據收集嘅基礎設施項目,而唔係即時上手型工具。