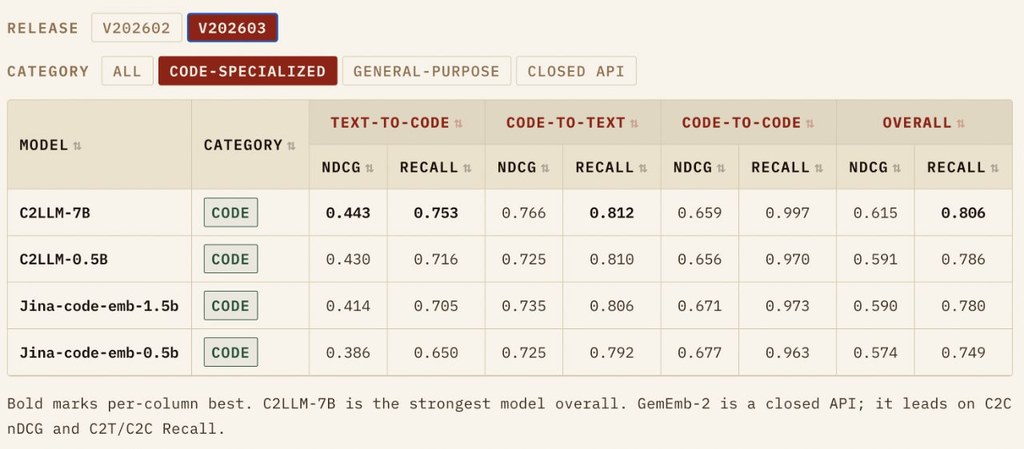
CoREB 係一個針對程式碼 embedding models 搜尋同 reranking 的評測基準,透過 LoRA 在混合重排序器語料庫上對Qwen3-Reranker-4B進行了微調。CoREB 分三種常見場景:用文字搵 code、用 code 搵相似 code,以及由 code 反推題目描述。一般人可以理解成:唔只測「搵唔搵到」,仲測「排位準唔準」。
實際使用上,你可以直接載入資料集,讀取 queries、qrels 同 code/text 語料,再用標準資訊檢索評分工具做評估;如果係模型開發者,亦可以接上兩階段流程,先做 embedding 檢索,再用 cross-encoder 重排。這個設計方便將現有搜尋模型快速放入同一把尺比較。
它最有價值的地方,係用三級相關性標註,將「真正答案」同「同題但錯嘅干擾項」分開,避免只係二元對錯。再加上問題切分唔重疊、涵蓋五種程式語言,令測試更貼近真實開發情境,而唔係只考記憶。
- 支援 Text-to-Code、Code-to-Code、Code-to-Text 三類任務
- 以三級相關性處理 hard negative,對排序更敏感
- 涵蓋 Python、C++、Java、Go、Ruby
- 訓練/測試分割避免題目重疊
- 適合比較檢索模型同 reranker 的整體效果
如果你做的是程式碼搜尋、AI coding assistant,或者想評估向量檢索加重排的完整流程,CoREB 會幾有參考價值。特別係想避免資料污染、又想睇模型喺唔同語言同任務之間的差異,呢個基準算係比較務實的一種選擇。