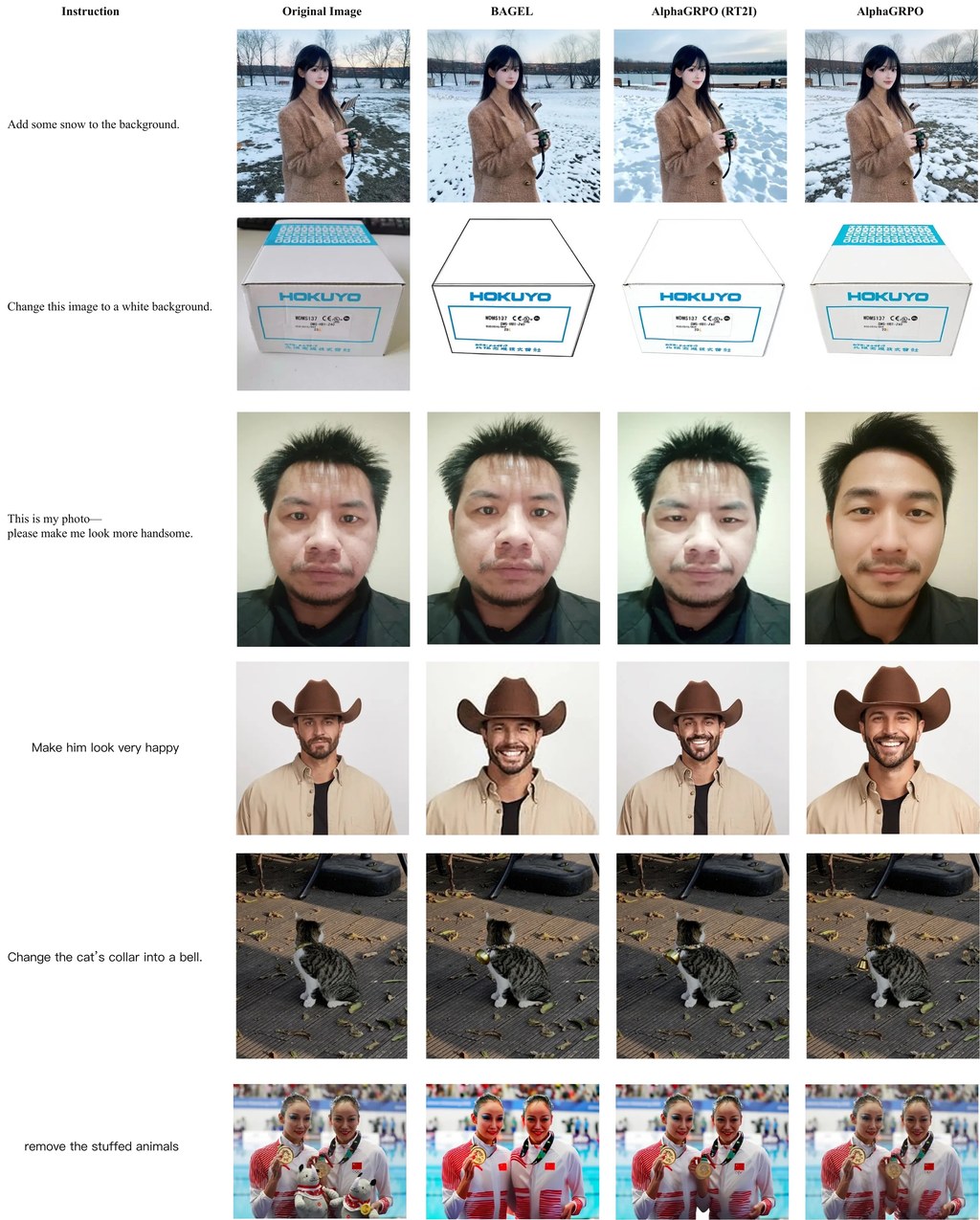
AlphaGRPO 係一個用喺原生統一多模態模型嘅訓練框架,重點係令模型唔只係「生成」,而係會根據提示主動推理,並喺輸出有偏差時嘗試自行修正。網頁內容指出,佢主要面向文字生圖同相關編輯場景,目標係改善細節理解、構圖一致性,同埋對隱含要求嘅掌握。
呢個方法特別之處,在於將 GRPO 引入 AR-Diffusion 類型嘅統一模型,而且唔需要額外 cold-start 階段。另一個核心設計係 DVReward:先將複雜指令拆成多個可核實嘅細問題,再由開源多模態模型按語意對齊同畫面品質提供較穩定、可解釋嘅回饋,避免只靠單一分數太過籠統。
如果你想理解點樣使用,概念上可以當佢係一種訓練或強化現有多模態生成模型嘅方法,而唔係一般終端用家即開即用嘅 App。較適合研究人員、模型工程師,或者需要改善文字生圖、細粒度屬性控制、影像編輯泛化能力嘅團隊參考同實作。
- 支援推理型文字生圖,能更主動補足用家未明講嘅意圖
- 可做自我反思式修正,生成後再檢查並調整錯配內容
- 回饋機制較細緻,將要求拆解成可驗證項目再評估
- 在多個生成基準上有一致進步,亦可遷移到編輯任務
- 推論階段加入自我修正後,文中指最高可再提升 5.8%
就評估結果而言,頁面提到 AlphaGRPO 喺 GenEval、TIIF-Bench、DPG-Bench、WISE 等生成基準,以及 GEdit 編輯任務都有提升,而且編輯能力並非靠專門編輯訓練得來,反映泛化表現不俗。不過,具體效果仍應按模型底座、評測設定同實際資料而定。
訓練程式碼和模型權重目前正在進行內部審核,審核通過後將予以發布。