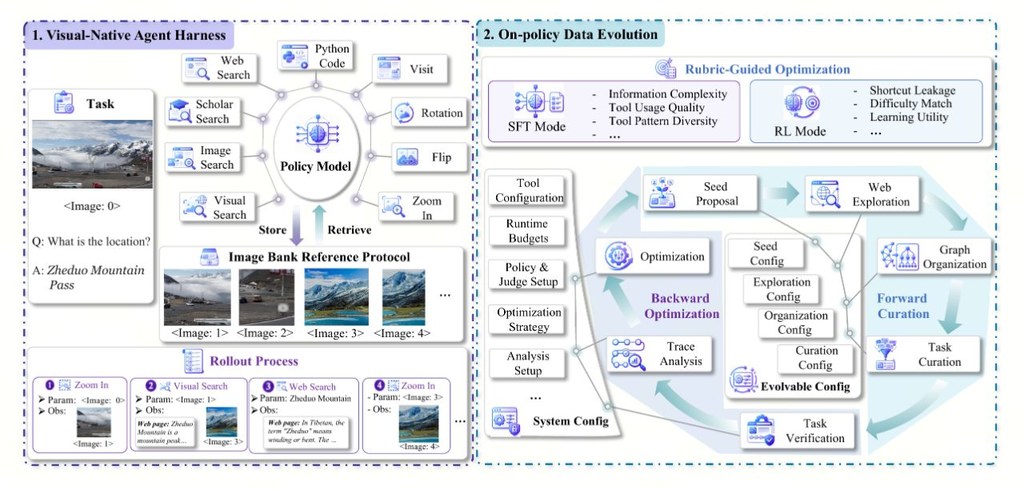
如果你對「會自己搵資料的 AI」有興趣,ODE 係一個幾值得留意的研究型專案。它唔係單純訓練模型直接輸出答案,而係讓代理按步驟去搜尋網頁、找圖片、查看學術結果,甚至對圖片放大、旋轉或翻轉,再整理證據作判斷。
對初學者來講,可以先將它理解為一個「工具操作訓練場」。專案目前已提供訓練程式、評估環境同公開工具整合,重點係同一套流程可同時用於測試與強化學習;不過自動化資料演化部分現時似乎仍在逐步補完。
它想解決的核心問題,是傳統靜態訓練資料未必足夠教到代理點樣靈活使用工具。ODE 的做法,是先用監督式訓練教基本動作格式,再用強化學習讓代理在真實互動中調整策略,之後分析操作軌跡,找出行為缺口,再回頭改善下一輪訓練資料。
比較特別的是,它把中途見過的圖片保存成可重用參照,之後可以再裁切、檢視或做視覺搜尋,唔使每次由零開始。這種設計對需要圖文交叉查證的任務尤其重要,亦比只靠文字搜尋的代理更貼近真實使用情境。
- 支援多種工具流程:網頁搜尋、圖片搜尋、學術搜尋、瀏覽頁面、視覺搜尋與本地圖片操作
- 著重保留中間圖像證據,方便後續步驟重用
- 訓練方式結合 SFT 與 RL,並用操作紀錄反推資料改進方向
- 已展示在 Qwen3-VL-8B 與 Qwen3-VL-30B 這類視覺語言模型上的提升
如果你本身做 AI 代理、檢索增強系統,或者關心模型如何可靠地「邊找邊想」,這個專案會有參考價值。對一般讀者而言,它亦提供了一個清楚例子:未來較實用的 AI,未必只係更大模型,而係更懂得在圖像與文字之間有條理地找證據。