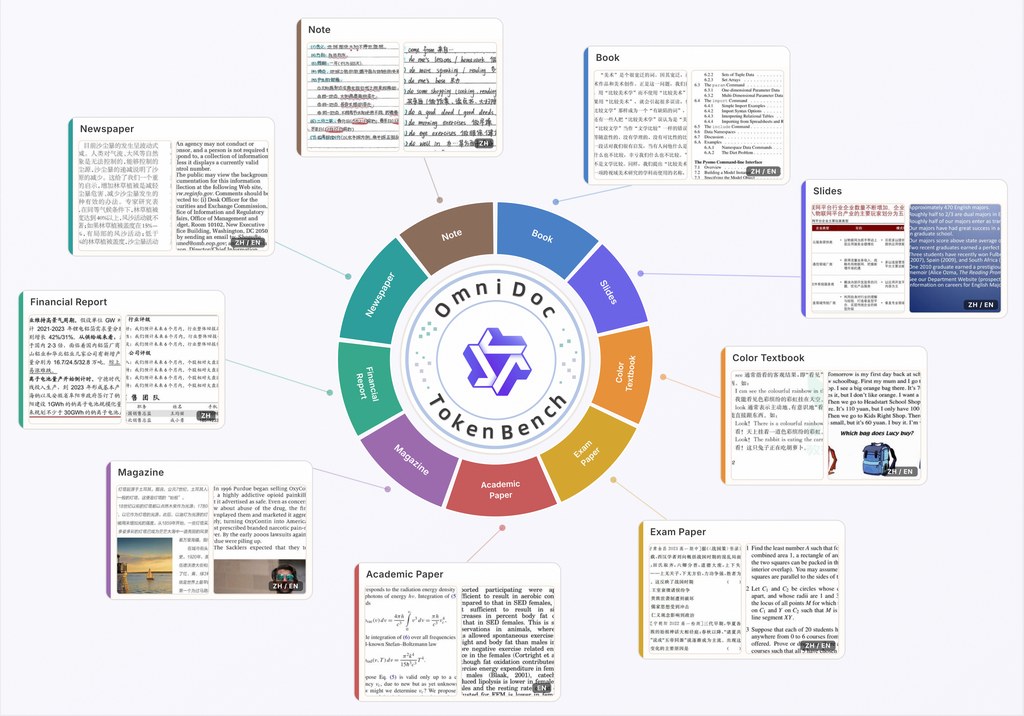
如果你有留意 AI 圖像模型,會知道一般圖片評分未必能反映「文字有冇走樣」。OmniDoc-TokenBench 的重點,正正是針對文件類圖片做評測,尤其適合檢查 VAE 重建之後,頁面上的字仲讀唔讀得清。
它提供約 3,000 張樣本,涵蓋書本、投影片、試卷、學術論文、雜誌、財務報告、報紙與筆記等類型,並且同時有中英文內容。相比只看普通畫質分數,這個基準多加了 OCR 相關比對,較貼近真實使用情境,因為文件圖片最重要的往往不是「靚」,而是「字準」。
上手方式大致算直接:先下載資料集,再用它附帶的評測工具,將你的重建圖片與原圖比較。工具會輸出整體結果,也可看到逐張圖片的 OCR 與字串距離表現;不過部分指標首次執行時需要額外下載模型權重,而 OCR 預設亦偏向 CPU,做大批量測試時可能要留意速度。
值得留意的是,它不是單靠 PSNR、SSIM 這類傳統指標,而是加入 LPIPS、FID,以及以 OCR 為基礎的 NED。對文件任務來說,NED 特別實用,因為它更能反映文字內容有冇被改錯;這亦是它相對一般影像基準較有針對性的地方。
- 適合評估文字密集的文件圖片重建效果
- 資料涵蓋九類文件,中英文都有
- 支援 PSNR、SSIM、LPIPS、FID、NED 等多種量度方式
- 可輸出整體分數,也可查看逐張圖片結果
- 文中提到相關模型背景來自 Qwen-Image-VAE-2.0,並比較不同壓縮設定與其他 VAE 表現
如果你是做文件數碼化、OCR 前處理、壓縮重建,或者正測試圖像自編碼模型,這個專案幾有參考價值。對一般讀者而言,可以將它理解成一把專為「文件圖片文字保真」而設的尺,幫你分清模型究竟只是畫面順眼,還是真的保住內容。