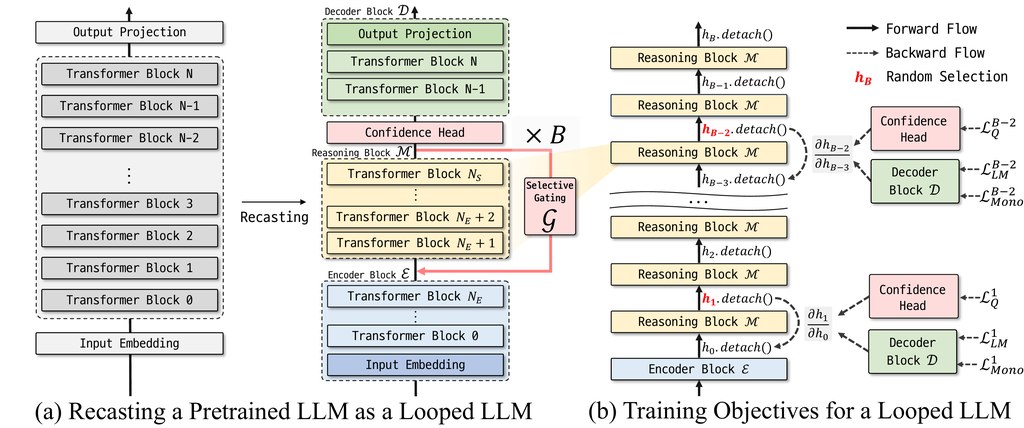
LoopUS 是一個針對大型語言模型的後訓練框架,核心想法不是叫模型輸出更長答案,而是先在內部隱藏表示上反覆「再諗一次」。簡單講,它把原本一次過運作的模型,拆成編碼、循環推理、解碼三部分,讓中間的推理區塊可以重用多次。
這種做法的實際用途,主要是令模型在回答較需要推理的問題時,可按需要投入更多計算量,而毋須由零開始訓練全新的循環式架構。對研究人員或工程團隊來說,這代表可以基於現有預訓練檢查點做改造,兼顧部署現實與訓練成本。
LoopUS 的創新之處,在於它不是盲目重覆中間層,而是先根據模型內部表示隨深度變化的特徵,決定邊部分適合拿來循環使用。同時,它加入選擇性閘門去減少反覆更新時的狀態漂移,並用較節省記憶體的監督方式訓練長迴圈,另外還有信心分數機制,推論時可提早停止,避免不必要的額外步數。
重點摘要:
– 把預訓練 LLM 重組成編碼器、循環推理區塊、解碼器
– 主要在隱藏空間做反覆精修,而非單純拉長輸出內容
– 以選擇性閘門穩定多輪迭代,減低表示崩壞風險
– 支援按輸入難度調節推論計算量,較重視效率
– 評估流程結合 lm-eval,訓練程式亦集中處理 checkpoint 與續跑
若你是做研究原型、推理能力比較,或想測試「同一模型可否用更多思考步數換取更好表現」,LoopUS 會特別值得留意。相對一般只追求生成更長文字的方法,它更像在模型腦內做多輪整理;不過實際收益仍取決於基礎模型、資料與任務設定。