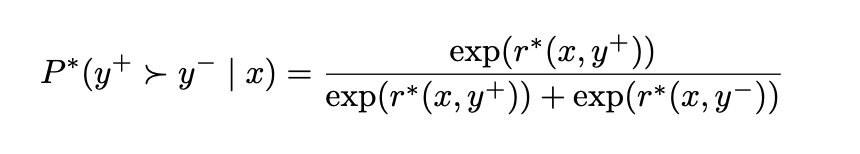
這個專案的核心,不是再訓練一個「黑盒」分數模型,而是先把人對圖片好壞的偏好,整理成可讀的文字評分準則。簡單講,系統會看一小批已標示「邊張較好」的圖片對,抽出判斷依據,再交給視覺語言模型作裁判,輸出成對訓練有用的獎勵訊號。
實際使用上,它較適合已有偏好資料的人員:例如你手上有兩張生成圖,並知道哪張較符合要求,系統就可根據這些例子自動產生 rubric。之後你可以檢查、保存和重用同一份準則文件,令後續訓練或比較更一致,而不是每次靠隱藏分數重新估計。
我認為這個專案最有意思的地方,是它把「評分理由」由隱性變成顯性。它不只會生成準則,還會用已標記例子反覆驗證與修訂;若準則判錯,就再調整,這比單純叫模型直接揀贏家更容易追查問題。論文亦指出,這類做法有助減少位置偏差,並提升少量標註下的效率。

- 最大特色:獎勵不再是看不到的分數,而是可閱讀的文字準則
- 流程較可驗證:生成後會對照標註樣本檢查,失敗就修訂
- 支援範圍實用:可用於文字生圖,也可處理帶來源圖的編輯任務
- 重用性高:準則可存成檔案,之後重複用於較穩定的訓練流程
最適合的場景,是你想微調圖片生成或圖片編輯模型,但又希望知道模型究竟憑甚麼作出偏好判斷。此專案已接好文字生圖的 FLUX.1-dev LoRA RPO,以及圖片編輯的 Qwen-Image-Edit LoRA RPO;作裁判的視覺語言模型則可用本地 Qwen3-VL(經 vLLM)或 OpenAI 相容端點。
整體來看,AutoRubric-as-Reward較像一套「把審美與要求寫清楚」的工具鏈,而不只是另一個評分器。對研究或進階開發者而言,它的價值在於透明、可檢查、可重現;但對一般用家來說,前提仍是你需要有成對偏好資料,以及願意花時間檢視準則是否真的反映你的標準。
以下係條式嘅詳細拆解:
1. 左手邊:$P^*(y^+ \succ y^- | x)$
- $x$:係指輸入嘅內容(Input/Prompt)。
- $y^+$ 同 $y^-$:係一對輸出。通常 $y^+$ 代表人類偏好嗰個(好嘅),$y^-$ 代表被捨棄嗰個(差嘅)。
- $\succ$:呢個符號代表「優於」或者「偏好」。
- 意思係「喺已知 $input$ 嘅情況下,人類偏好 $y^+$ 多過 $y^-$ 嘅機率」。
2. 右手邊:分數分配
呢個部分係用嚟將「好感度」量化:
- $r^*(x, y)$:呢個係獎勵函數 (Reward Function)。你可以想像成模型幫每一個輸出打嘅「分」。分數越高,代表嗰個輸出越符合人類偏好。
- $\exp(\dots)$:即係指數函數 $e^x$。用指數係為咗確保計出嚟嘅數值係正數,而且可以放大分數之間嘅差距。
3. 成條式嘅邏輯
$$P^*(y^+ \succ y^- | x) = \frac{\exp(r^*(x, y^+))}{\exp(r^*(x, y^+)) + \exp(r^*(x, y^-))}$$
呢個結構其實同我哋平時見嘅 Softmax 或者 Sigmoid 函數好似:
- 分子:係偏好輸出 ($y^+$) 嘅得分。
- 分母:係兩個輸出($y^+$ 同 $y^-$)得分嘅總和。
- 結論:如果 $y^+$ 嘅得分比 $y^-$ 高好多,分子就會佔分母好大比例,機率就會接近 1(代表好肯定人類會揀 $y^+$)。如果兩者得分差唔多,機率就會接近 0.5(代表人類覺得兩個都差唔多)。
總結
呢條式喺訓練 AI(例如 RLHF 或者 DPO)嗰陣好重要,佢幫模型學識點樣根據人類嘅選擇,去調整背後嗰個 $r^*$ 獎勵分數,令模型之後生成嘅嘢越來越接近人類鍾意嘅答案。
Source: https://github.com/OpenEnvision/AutoRubric-as-Reward