PAE 是一個為潛在擴散模型而設的自編碼器框架,重點不只是把圖片壓縮再還原,而是先把潛在空間整理成更適合擴散模型學習的形態。簡單講,它關心的不是「壓得靚唔靚」,而是「模型之後生圖時會唔會更順、更穩定」。
實際使用上,PAE 可理解為擴散模型前面的 tokenizer 或影像編碼模組:先把圖片轉成 latent,再交畀後續生成模型訓練。這種做法特別適合本身已在做 latent diffusion、但覺得收斂慢、訓練成本高,或者生成效果未夠穩定的研究與開發流程。
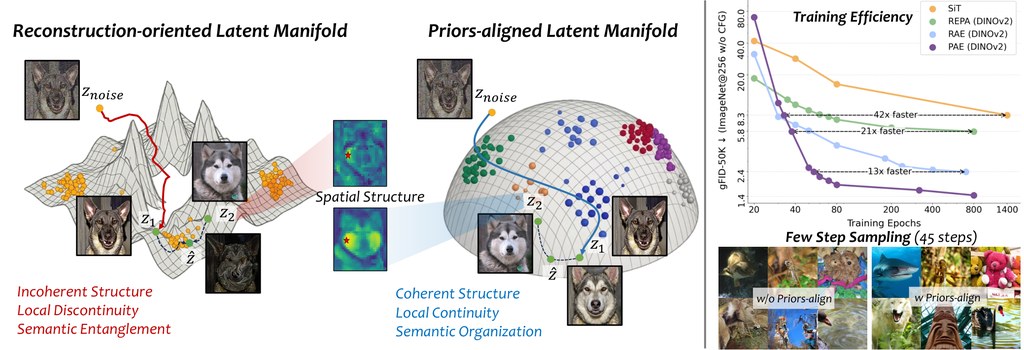
這個專案較有意思的地方,是它明確提出三個「對擴散友善」的潛在空間特質:空間結構一致性、局部流形連續性,以及全域語意組織。作者不是假設這些特質會自然出現,而是用三種 prior-alignment regularization 去主動約束,這比單靠重建誤差的傳統思路更進一步。
根據專案提供的結果,PAE 在 ImageNet 256×256 上做到 gFID 1.03,並且在相同 LightningDiT 設定下,收斂速度最高可比 RAE 快 13 倍。對非研究人員而言,這代表同樣資源下有機會更快見到可用成果;不過這些表現仍應視乎資料集、訓練設定與骨幹模型而定。
- 核心定位:為 latent diffusion 準備更易學的潛在表示
- 主要創新:把「擴散友善」拆成三個可優化的性質來訓練
- 實際價值:有機會縮短訓練週期,提升生成質素與少步數採樣表現
- 適合場景:影像生成研究、需要高效率訓練的生成系統、比較不同 tokenizer 設計
- 可配骨幹:支援多種編碼器方向,包括 DINOv2、SigLIP2、DINOv3、MAE
如果你關心的是「如何令擴散模型學得更快,而唔係只換更大模型」,PAE 的切入點相當值得參考。它最適合有一定生成模型流程的人採用;對一般用家而言,未必是即裝即用工具,但作為下一代 latent tokenizer 的設計思路,含金量相當高。