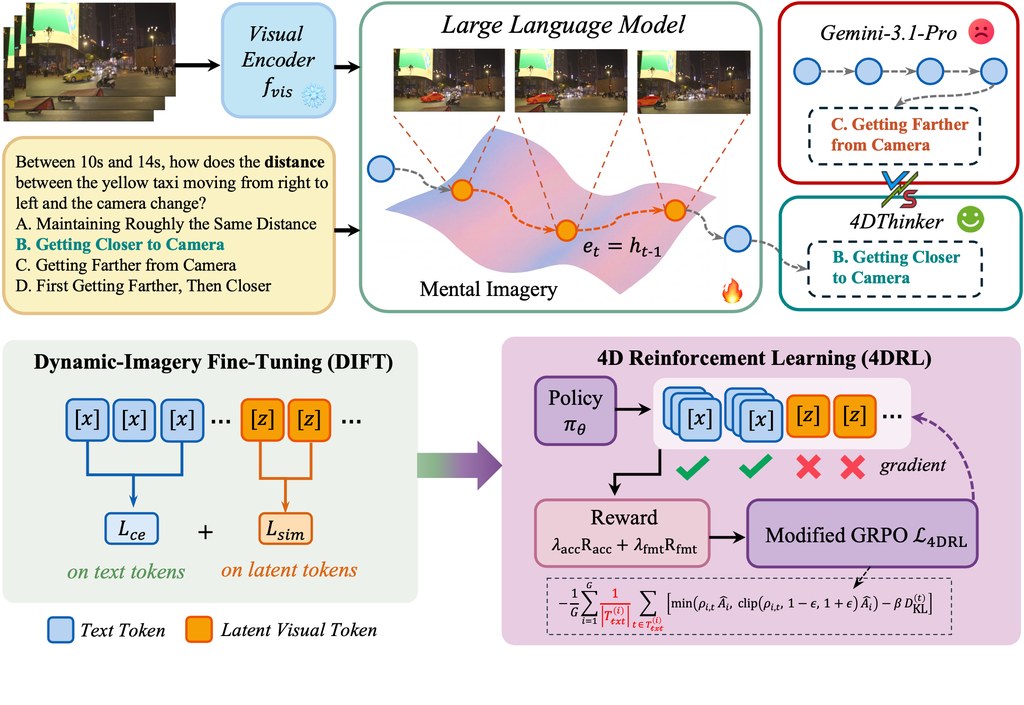
4DThinker 是一個面向研究用途的視覺語言模型框架,重點不是單純描述影片內容,而是讓模型從單鏡頭影片理解物件如何移動、互相影響,以及場景隨時間怎樣變化。簡單講,它想解決「模型見到影片,能否真正理解空間變動」這件事。
它的實際用法較接近訓練與評估流程,而不是即裝即用的消費級工具。專案提供資料集、模型權重、訓練程式,以及前處理所需資源;若要重現效果,需準備影片資料、SAM3 checkpoint,並以 Qwen2.5-VL-3B-Instruct 作為基礎模型,部分資料生成流程亦會用到 OpenAI 相容 API。
這個專案最值得留意的創新,在於它不再只靠文字一步步「講出」推理過程,而是加入所謂 4D latent imagery,讓模型在隱藏空間中模擬場景演化。配合 DIFT 微調,以及 4DRL 強化學習,方向上是希望把動態視覺理解能力直接學進模型本身,而非額外串接複雜幾何模組。
重點摘要:
– 針對單鏡頭影片的動態空間推理
– 提供資料生成、訓練與評測相關組件
– 以 4D 潛在表徵處理時間與空間變化
– 支援調整 latent token 數量與損失權重
– 較適合研究團隊,而非一般用家直接部署
如果你做的是機械人感知、影片問答、場景理解,或者想提升模型對「之後會怎樣」的判斷,4DThinker 特別值得留意。至於一般內容摘要或靜態圖片分析,它未必是最直接的選擇,因為整個設計明顯是為動態推理而生。