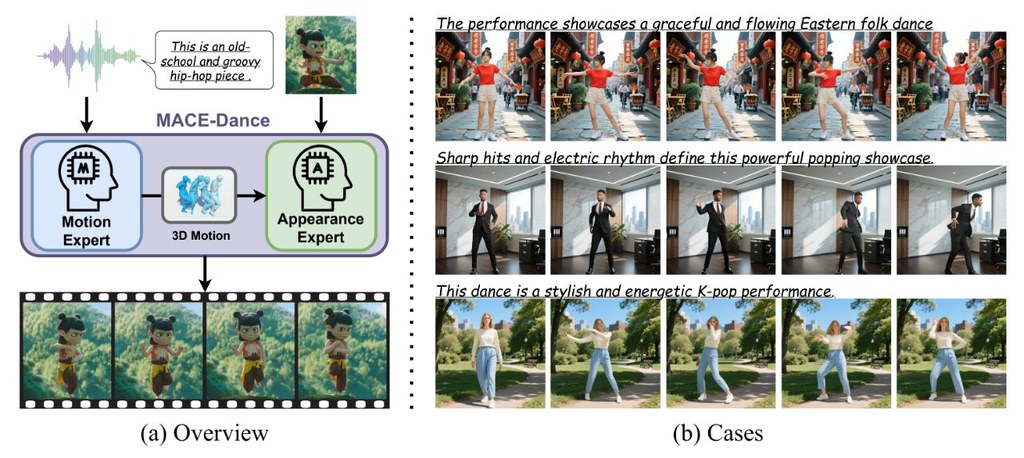
MACE-Dance 是一個面向音樂驅動舞蹈影片生成的研究型專案,核心目標是讓系統根據音樂內容,產生具有舞蹈動作與角色外觀一致性的影片。從名稱與簡介來看,它特別強調 motion 與 appearance 的分工建模,而不是把整個生成流程視為單一路徑處理。
這個專案最值得注意的地方,在於所謂 Motion-Appearance Cascaded Experts 的設計思路。簡單說,它像是把「先決定怎麼跳」與「再決定畫面怎麼呈現」拆成串接的專家模組,這種做法理論上有助於減少動作節奏與人物外觀彼此牽制的問題,也更貼近舞蹈影片生成常見的兩大難點。
實際使用上,這類儲存庫通常更適合已有生成式影音或人體動作研究背景的開發者與研究者。若你想評估模型表現,重點應放在輸入音樂後的動作對拍程度、角色連續性,以及生成影片是否維持合理的視覺一致性;若要延伸研究,則可觀察其模組拆分是否方便替換不同的音樂表徵或影像生成元件。
- 聚焦音樂到舞蹈影片的多模態生成任務
- 以動作與外觀分階段處理作為主要方法亮點
- 適合分析節奏對齊、角色一致性與影片連續性
- 較偏研究用途,不像一般即裝即用的消費型工具
就應用場景而言,它最適合用在舞蹈生成研究、虛擬人表演合成、音樂視覺化內容製作,以及多模態生成模型的比較實驗。若你正在找的是可快速產出商業級短影音的完整產品,這個專案目前看來更像方法驗證與學術探索平台;但若你的目標是理解音樂驅動角色影片生成的前沿方向,它具備相當明確的研究切入點。