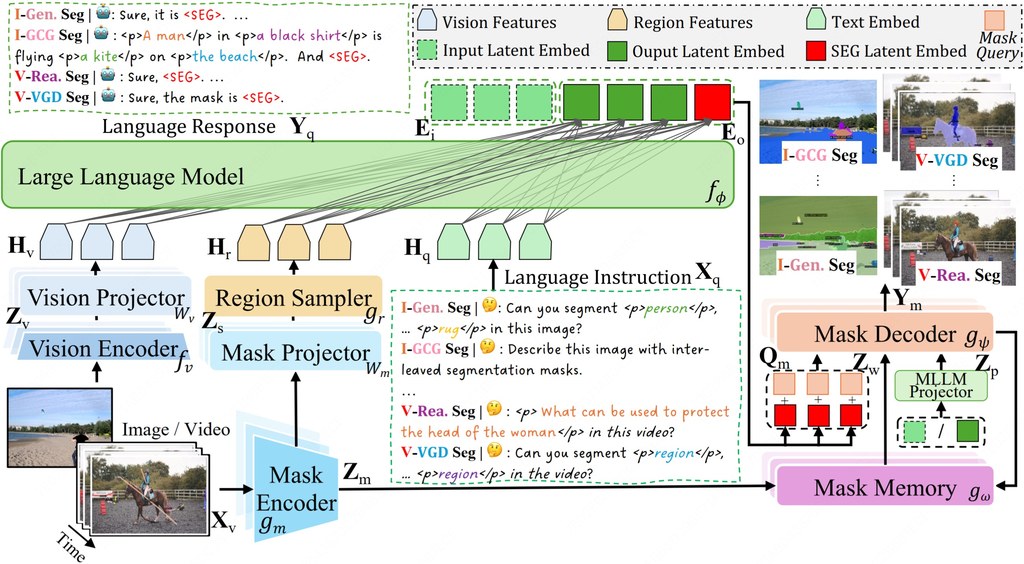
X2SAM 是一個統一式分割多模態大型語言模型,目標是把影像中的「任意分割」能力延伸到影片。它結合 LLM、Vision Encoder、Mask Encoder、Mask Decoder 與 Mask Memory,讓模型不只理解畫面內容,還能依照對話指令或視覺提示產生像素級遮罩。
實際使用上,X2SAM 可同時接受對話式文字指令與視覺提示,適合需要指定目標、追蹤物件或互動修正結果的情境。官方描述指出,它支援 generic、open-vocabulary、referring、reasoning、grounded conversation generation、interactive 與 visual grounded segmentation,代表使用者可用較自然的方式提出分割需求,而不必侷限於單一輸入形式。
這個專案的主要創新,在於用單一介面整合影像與影片分割,並以 Mask Memory 儲存受引導的視覺特徵,改善影片中跨時間的遮罩一致性。此外,作者也提出 V-VGD(Video Visual Grounded) 分割基準,用來評估模型是否能根據互動式視覺提示,在影片中分割並追蹤物件。
- 統一支援影像與影片分割,而非只專注單一媒體
- 同時支援文字指令與視覺提示輸入
- 透過 Mask Memory 強化影片遮罩的時序一致性
- 提出 V-VGD 基準補足影片視覺定位分割評估
- 採用異質影像與影片資料的聯合訓練策略
從工作應用來看,這類系統可望受惠於影片內容理解、互動式標註、智慧剪輯、視覺助理與多模態人機互動等任務。性能方面,原文表示 X2SAM 在影片分割上達到強勁表現,對影像分割基準仍具競爭力,並保留一般影像與影片聊天能力;不過此頁面未完整列出具體數值,因此解讀上仍應以論文與實驗表格為準。
模型列表:LLM、SAM 系列