Will AI Replace Filmmakers?

AI 已經深度進入影視產業,包括腳本輔助、分鏡、配樂、剪接、去噪、Roto、魔術遮罩、背景生成、群眾演員替代、配音克隆與去老化特效等。
導演主張未來是「AI 和創作者」的混合模式,而不是二選一:AI 強化視覺與流程,人類負責情感、品味與敘事判斷。
真正的風險在於資方把 AI 當成「捷徑」來節省人力成本,壓縮藝術與勞動,而不是把它當作創作工具。
(more…)AI 已經深度進入影視產業,包括腳本輔助、分鏡、配樂、剪接、去噪、Roto、魔術遮罩、背景生成、群眾演員替代、配音克隆與去老化特效等。
導演主張未來是「AI 和創作者」的混合模式,而不是二選一:AI 強化視覺與流程,人類負責情感、品味與敘事判斷。
真正的風險在於資方把 AI 當成「捷徑」來節省人力成本,壓縮藝術與勞動,而不是把它當作創作工具。
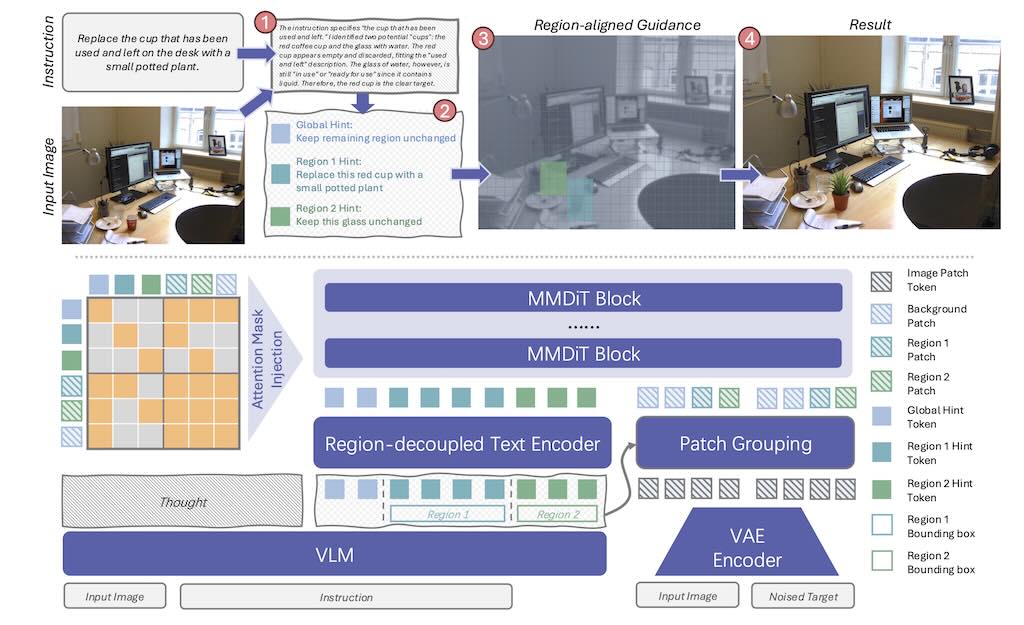
(more…)RePlan 是一個基於指令的圖像編輯框架,專門解決指令-視覺複雜度(IV-Complexity)挑戰,透過視覺語言規劃器與擴散編輯器結合實現精準區域編輯。

框架採用「規劃-執行」策略:VLM 規劃器透過逐步推理分解複雜指令,生成邊界框與區域提示;編輯器使用無訓練注意力區域注入機制,支援單次多區域並行編輯,避免迭代 inpainting。
– Google Deepmind A.I.

影片討論了中國AI技術在多模態模型和圖像生成方面的重大突破,以及中國在全球AI競賽中逐漸展現出的技術和能源優勢,對未來產業格局產生深遠影響。
中國在電力產能上的快速增長(目前佔全球30%以上,並以每18個月增加一個美國總產能的速度擴張),將成為未來AI競賽的關鍵優勢,因為AI訓練和應用極度依賴能源供應。

人工智慧與機器學習教授 Graham Morehead 回答網友對AI相關的熱搜問題!AI、AGI 和 ASI 之間有什麼區別?如果中國或美國率先實現超級人工智慧,將會產生什麼影響?AI會搶走人類的所有工作嗎?以上這些問題的解答都在本集影片中!

ComfyUI-Manager 在 3 月 28 日遷移至 ComfyUI 開發團隊所在的 GitHub Repository。因此我相信 ComfyUI 能夠持續提升使用者體驗。提供一鍵安裝、節點管理。如果您經常探索最新的 AI 繪圖技術,抑或需要特定的圖像處理節點,ComfyUI Manager 都能夠令相關操作流程更為簡易及高效。
OpenAI 正式宣佈將會在它們的產品 ChatGPT 與及桌面應用程式中添加 Anthropic 的上下文協議 (MCP) 的支援。 OpenAI CEO Sam Altman 表示 “我們很開心能夠在我們的產品中增加對 MCP 的支持”。

Embedding 文字嵌入,意思是將文字轉換為有意義的向量數值。其主要目的是為了讓 A.I. 開發者能夠利用這些向量,實現更精準的語義搜尋,即使查詢與文本內容的詞彙不完全相同也能找到相關資訊。
Google 宣布推出一個新的實驗性 Gemini 文字嵌入模型,稱為 gemini-embedding-exp-03-07。這個模型繼承了語言和細微語境的理解,適合廣泛的應用。這個新模型超越了 Google 之前的最先進模型,並在多語言文本嵌入基準測試(MTEB)中名列前茅,同時還提供了更長的輸入長度等新功能。目前已經可以透過 Gemini API 開始使用。

DeepSeek 開放源碼週(Open Source Week)是由中國人工智能初創公司 DeepSeek 在 2025 年 2 月 24 日至 2 月 28 日舉辦的一項活動,旨在展示它的建構開放、同埋協作性 AI 生態系統的承諾。在此期間,DeepSeek 每天發布一個開源代碼庫,總共有五個,這些代碼庫已在實際環境中得到驗證並已經開始應用於線上服務。

谷歌的 Titans 架構靈感來自人類記憶方式,包括短期、長期和持久記憶。Titans 的長期記憶能夠主動搵出相關資訊及時更新,而持久記憶就可以儲存推理技能,因此能夠擴展前文後理,並且能夠保持高準確性。
