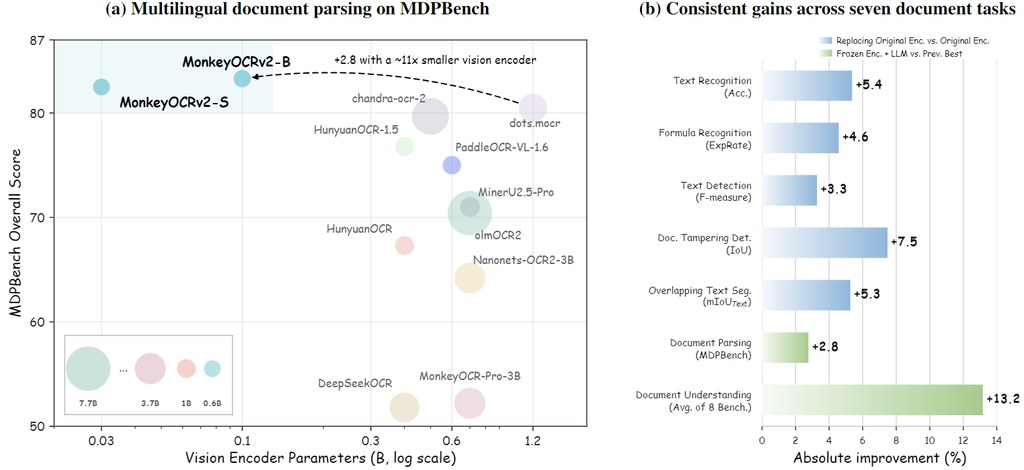
當你想喺有限 GPU 預算下做影像生成、編輯,甚至延伸到影像與影片理解,Mage 這個開源模型家族的定位就相當直接:用固定 4B 參數規模,處理多模態理解與生成兩條路線,目標唔係堆大模型,而係保留研究可控性同部署可行性。
Mage 目前最完整的是 Mage-Flow,屬於模型家族中的生成與編輯分支。它把 Mage-VAE 同 Native-Resolution Multimodal Diffusion Transformer 組合起來,前者負責更高效率的 latent tokenizer,後者負責文字生圖與指令式修圖;同時提供 Base、RL-aligned 同 4-step Turbo 版本,方便按畫質、對齊程度與速度取捨。另一條線 Mage-VL 對準 image/video understanding,但程式與權重細節仍待釋出。
同類開源影像模型很多都靠更大參數量換效果,Mage 的判斷明顯不同:它把重點放喺 codec-aligned efficiency,同一個 checkpoint 已可覆蓋 512 到 2048、不同長闊比,連 4:1 這類極端尺寸都原生支援,減少多套模型或額外縮放流程。它在生成、編輯表現上可與 Qwen-Image 20B、FLUX.2 32B、FireRed-Image-Edit 20B 等較大型開源系統競爭,但取捨是 Mage-VL 仍未完整開放,整個家族現階段更適合關注研究與工作流整合的人先行評估。

- 固定 4B 規模,主打可訓練、可微調、可部署
- Mage-Flow 已覆蓋 text-to-image 與 instruction-based image editing
- Mage-VAE 以更低 encode/decode MACs 減輕高解析度瓶頸
- 單一 checkpoint 支援 512–2048 與多種 aspect ratio
- Turbo 版本強調速度,1024² 在單張 A100 有明確推理數字
部署與測試方面,現有資料顯示 Hugging Face 已提供多個 Mage-Flow 與 Mage-Flow-Edit 權重,適合先用現成 checkpoint 驗證生成、修圖與速度,再決定是否進一步做微調。對做垂直領域影像項目、想研究後訓練方法,或者需要把高解析度生成放入較實際算力條件的人,Mage 的吸引力不在花巧包裝,而在它用一條輕量路線,把研究、性能與部署成本拉回較平衡的位置。