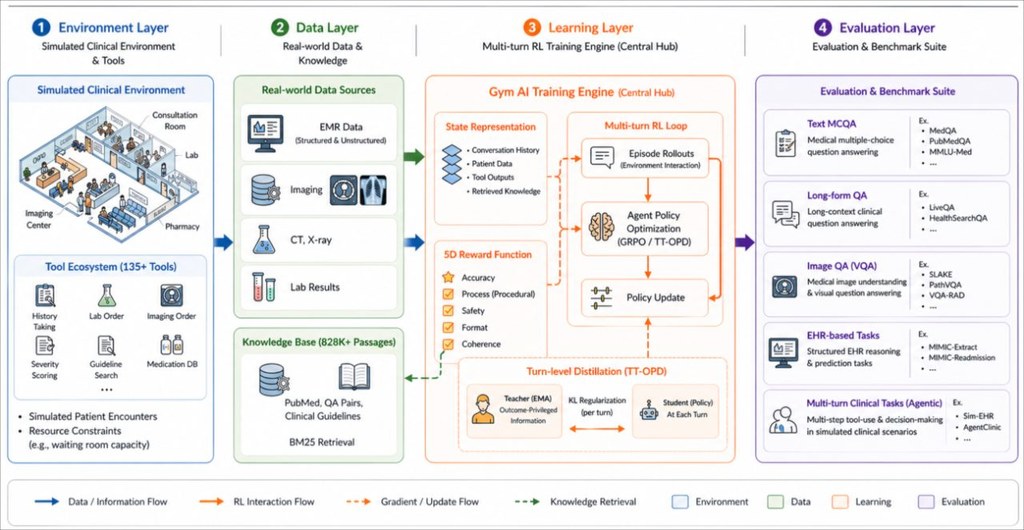
Healthcare_GYM 是一個相容 Gymnasium 的醫療 AI 訓練環境,核心目的不是單純問答,而是讓代理在多回合流程中學會查資料、呼叫工具並完成臨床任務。它涵蓋 10 個臨床領域、3,600 多個任務與 135 個專用工具,並把 82.8 萬筆醫療段落納入可檢索知識庫。
實際使用上,它比較像給研究團隊的「醫療代理測試場」。若你已經有強化學習流程,就能透過標準的環境互動介面,把代理接到任務、工具呼叫與回饋函數上,觀察模型在臨床推理、資訊檢索與多步驟決策中的表現。
這個專案最值得注意的創新,是提出 TT-OPD 這套多回合代理式 RL 的自蒸餾方法。從說明來看,作者認為 teacher 會隨學生探索而逐漸過時,因此蒸餾價值主要集中在訓練前期,並以 EMA 教師與週期性硬同步控制師生偏移,而不是長期依賴固定 teacher。
從結果來看,它在 18 個基準中的 10 個拿到最佳成績,平均比非 RL 的代理基線高出約 3.9 個百分點。不過資料也顯示,代理式評估未必在所有知識回憶型任務都占優,代表這套框架更適合需要檢索、工具操作與多步推理的情境,而不是只比裸模型記憶能力。
- 重點摘要
- 支援多回合臨床工具使用,不只是靜態醫療問答。
- 知識來源包含 PubMed 摘要、臨床指引與醫學教科書。
- 以 BM25 檢索 82.8 萬筆醫療段落,工具呼叫直接納入動作空間。
- TT-OPD 以 EMA teacher 與分階段淡出蒸餾來穩定訓練。
- README 指出實驗使用 Qwen3.5-9B 骨幹模型。
整體而言,Healthcare_GYM 最適合醫療代理、臨床決策輔助研究、RAG 結合工具使用的 RL 訓練,以及需要比較不同代理策略的學術實驗。若你的目標是建立可重現的醫療 agent benchmark,這個專案提供的環境設計與訓練觀點都相當有參考價值。