Meta FAIR 的「Code World Model (CWM)」是一個 32B 參數、專門為「帶世界模型的程式碼生成研究」設計的開放權重 LLM。它的關鍵點是:不只學 code syntax,而是透過大量「執行軌跡」去內化程式執行對系統狀態的影響,並在多任務 RL 下強化 agentic coding 能力。
CWM 是什麼?
- CWM(Code World Model)是一個 32 億參數(32B)、dense、decoder‑only 的 Transformer LLM,主要面向程式碼生成與程式相關推理。
- 它被設計成「世界模型式」的 code LLM:不只預測下一個 token,而是學會在腦中「模擬程式執行過程」及其對環境狀態的影響。
- 官方目標是提供一個強大的開放權重 testbed,讓研究者探索「世界模型 + agentic reasoning/planning」如何提升程式碼生成與軟體工程工作流。
訓練流程與 world modeling 設計
CWM 的訓練 pipeline 不是單純「pretrain → SFT」,而是刻意插入 world‑model mid‑training,再加上多任務 RL:
- 前期:先在一般語言與程式碼資料上做大規模預訓練,建立廣泛的語言、程式知識基礎。
- Mid‑training(世界模型核心):
- 在大量「observation‑action 軌跡」上進一步訓練,這些軌跡來自 Python interpreter 執行 trace,以及在 Docker container 中以 agent 方式操作系統的互動紀錄。
- 這類資料讓模型看到「程式片段/指令 → 執行過程 → 輸出與系統狀態變化」,等於學習一個對應「code → world dynamics」的隱式世界模型。
- 後期 post‑training:
- 先進行 supervised fine‑tuning,引入明確的 reasoning format、step‑by‑step 推理風格等標註資料。
- 再用 multi‑task RL(文中提到使用 GRPO 類型方法)在可驗證的 coding 任務、數學問題、多輪軟體工程環境中進行強化學習,reward 來自於測試通過率、解答正確與任務完成度。
這種設計的重點是:讓 RL 是「從已經具備世界模型的基底」開始,而不是只在純 token LLM 上做 RL,理論上比較容易學到長程規劃與工具使用策略。
模型架構與上下文長度
- CWM 是一個 64 層的 decoder‑only Transformer,採用現代 LLM 常見配置(例如 RoPE 位置編碼、SwiGLU FFN、GQA 等)。
- 參數規模為 32B,詞彙表約 128k token,明顯針對大型 codebase 與多語言程式碼場景設計。
- 上下文長度最高達約 131k tokens,可容納整個專案、多檔案上下文與長程互動軌跡。
- 為了處理這種長上下文,它使用「交錯式注意力」:
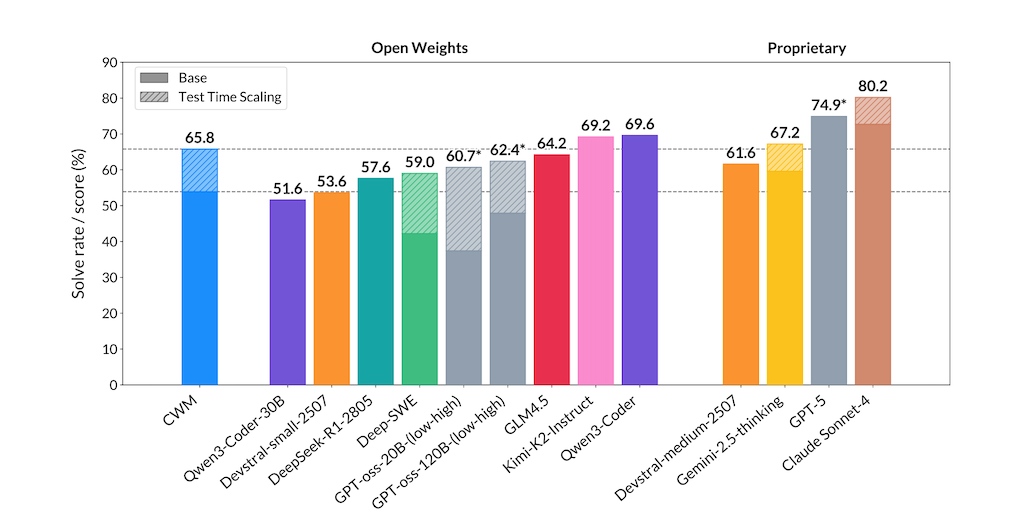
基準測試成績
在多個開源 benchmark 上,CWM 以 32B 級別達到非常有競爭力甚至 SOTA 的表現:
- SWE‑bench Verified:pass@1 約 53.9%(不做 test‑time scaling),在採用 test‑time scaling 後可達約 65.8%。
- LiveCodeBench:v5 約 68.6,v6 約 63.5(pass@1)。
- 數學與推理:
- 論文與解讀都提到:在同等或相近參數規模的開放權重 LLM 中,CWM 在一般 coding 與更 agentic 的軟體工程任務上都具有「best‑in‑class」水準,甚至接近或追平一些封閉大模型。
對你這種做 RAG / agent / tools‑calling 工作流的人來說,這顆模型的亮點其實是「在環境中操作和修 bug 的能力」,而不只是單輪 code completion 分數。
權重釋出與取得方式
- Meta 以「開放權重」形式釋出 CWM,提供多個 checkpoint:
- mid‑training 後的 world‑model 版本。
- SFT 後版本。
- RL 後完整版。
方便研究者分析各階段對能力的影響。
- 社群整理指出,CWM 權重目前在 GitHub 與 Hugging Face 上提供,包含 transformers 版權重與推理程式碼;Meta 採用自家訂定的 open‑weights 授權條款,主要定位在研究用途,具體使用限制需看 AI at Meta 官方頁與 HF model card 條款。
- Hugging Face transformers 已內建
CwmForCausalLM與對應 tokenizer。
與一般 code LLM 的本質差異
和傳統只在「靜態 code corpora + 少量程式執行資料」上訓練的 code LLM 相比,CWM 的幾個關鍵差異:
- 訓練核心是「大量程式執行與 agent interaction 的軌跡」,把「程式 → 執行 → 狀態變化」當成序列學習對象,形成隱式世界模型,而不只是 code token 統計模型。
- RL 設計是圍繞「可驗證結果」(例如測試通過、問題解答正確、多輪任務完成),而不僅是人類偏好/指令跟從,這對長程規劃與工具調度尤其重要。
- 長上下文 + 交錯 attention 讓模型可以在一次推理中讀完整個 repo、ticket 歷史與多輪 log,這是很多傳統 code LLM 現階段比較薄弱的地方。