tLLM 是 vLLM 推論引擎的運行時擴展層,提供生產者/消費者(Producer/Consumer)架構,能在生產環境中訓練和管理蒸餾器。
tLLM 的角色
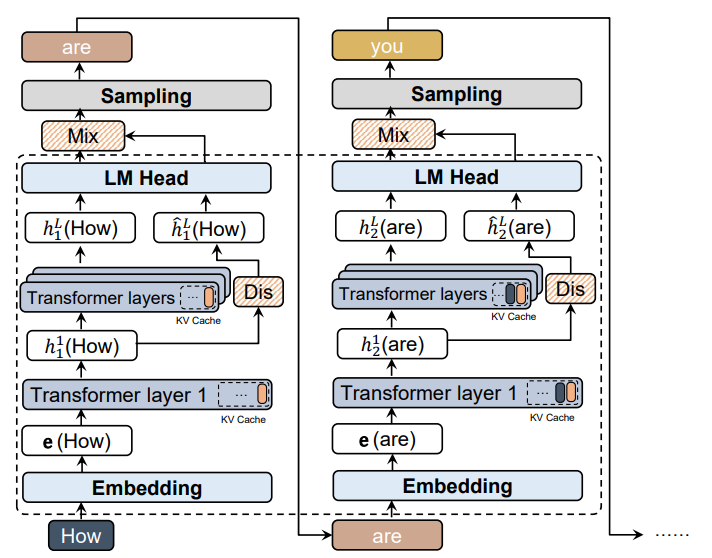
- 生產者管道:從 vLLM 推論中即時捕捉 LLM 的深層隱藏狀態(latent representations)
- 消費者管道:非同步訓練輕量 MLP(~1M 參數),這就是 Latent Distiller(潛在蒸餾器)
tLLM 可應用於醫療問答系統中,提升 RAG 生成的多樣性與準確性,特別適合配合 MedGemma 專案。 透過 ESamp (Exploratory Sampling )方法,在高吞吐 vLLM 服務下動態訓練輕量蒸餾器,引導模型探索未見語義區域,避免重複答案。
案例:醫療 RAG 系統
假設您建置一個基於 MedGemma 的繁體中文醫療 RAG 系統,處理患者查詢如「糖尿病併發症預防」。
- 標準 vLLM:依賴檢索文件生成單一答案,易陷入常見模式,Pass@1 低於 60%。
- tLLM + ESamp:啟用生產者管道捕捉隱藏表示,消費者訓練 Latent Distiller(MLP,~1M 參數),使用預測誤差作為新穎度信號。
- 運行流程:批次 32 查詢並行生成,蒸餾器線上更新(<5% 開銷),重新取樣產生多樣候選(如生活調整、藥物、飲食多視角),Pass@k 提升 20-30%。
此案例在 RTX 4090 上吞吐 4000+ tokens/sec,適合部署於 WhatsApp 查詢閘道,提升 Cantonese/繁中醫療 NLP 效能。 程式碼範例:整合 tLLM 至 vLLM Engine,engine = TLlmEngine.from_engine_args(engine_args) 啟動生產者/消費者。