100+ AI Videos That Look EXACTLY Like Reality (Veo 3)

1.3B 模型採用 Creative Commons 非商業授權,14B 模型則為 Apache 2 授權。
影片詳細展示如何在ComfyUI中下載、載入不同模型,根據顯存選擇合適的模型版本,並調整參數以優化生成效果(如步數、強度等)

人工智慧與機器學習教授 Graham Morehead 回答網友對AI相關的熱搜問題!AI、AGI 和 ASI 之間有什麼區別?如果中國或美國率先實現超級人工智慧,將會產生什麼影響?AI會搶走人類的所有工作嗎?以上這些問題的解答都在本集影片中!

Absolute Zero 是由清華大學主導的一項創新語言模型訓練方法。這個方法最顯著的特點是不再需要由人類提供的數據進行訓練,而是自動生成問題,然後嘗試自動解決問題來進行學習。過往的監督學習,或者強化學習,一般都是由人類設定目標進行監管,而 Absolute Zero 可以透過自我對弈機制。能夠在數學和程式設計的領域中自動提升推理能力。研究顯示,這種模型不僅在這些領域達到了最先進的性能,甚至超越了由人類策劃的數據去訓練的模型。

Trae 令我放棄了 Cursor,放棄了 WindSurf,甚至 Cline 等等。因為它擁有更加直觀的操作介面,除了提供傳統的 IDE 功能,亦包括自動編寫代碼、項目管理、插件管理,同時,最新版本亦都直接整合了 MCP 同 MCP 市場。當然亦唔少得 AI Agent。


💥 FaceFusion 3.2.0 更新不僅帶來了全新的GPU加速,還提升了不少效能與真實感!
🔍 新功能
1️⃣ YOLO NSFW過濾
2️⃣ 多GPU支援
3️⃣ FLAC音訊輸出
4️⃣ 臉部選擇增強

LTX-Video 是第一個基於 DiT 的視訊生成模型,可以即時產生高品質的視訊。它可以以 1216×704 的分辨率生成 30 FPS 的視頻,比觀看這些視頻的速度還快。該模型在多樣化影片的大規模資料集上進行訓練,可以產生具有逼真和多樣化內容的高解析度影片。模型支援文字轉圖像、圖像轉影片、基於關鍵影格的動畫、影片擴充(正向和反向)、影片轉影片以及這些功能的任意組合。




Skywork 是一個創新的研究團隊,致力於推動法學碩士和多模式理解。它們的使命是透過視覺和語言開發並實現無縫互動的尖端模型和資料集來突破人工智慧的界限。模型支援文字到視訊(T2V) 和圖像到視訊(I2V) 任務,並且可以在同步和非同步模式下進行推理。
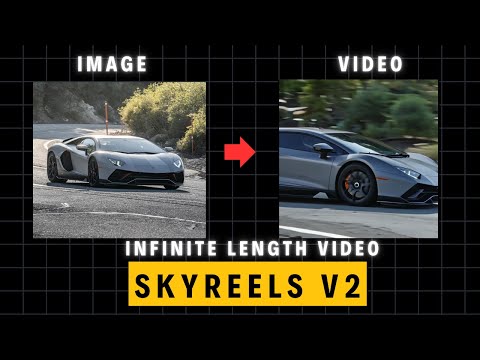
影片長度限制的突破:雖然像 LTXV 和 HuanYun 等模型在速度或品質方面表現出色,但它們通常限制生成約 5 到 10 秒的短片。Frame pack 可以生成高達 60 秒的高品質影片,但 60 秒是其最大長度。Skyreels V2 透過其稱為「擴散強制 (diffusion forcing)」的技術,可以讓您生成長達 60 秒甚至可能更長的影片。技術上,擴散強制模型可以透過不斷訓練一個擴散強制取樣器並在最後組合每個結果來無限延長影片長度。