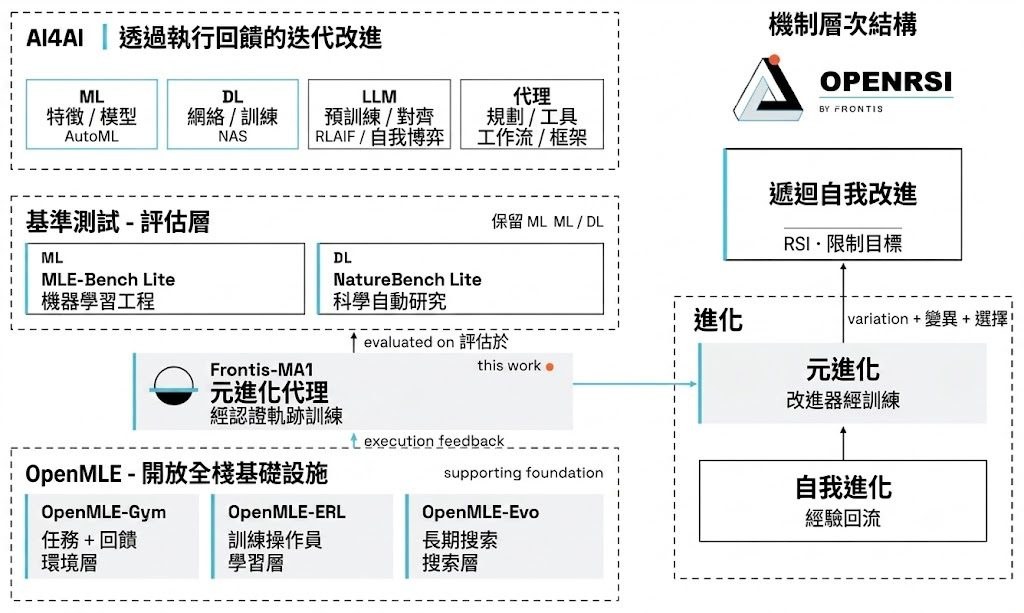
Reasonix 是 DeepSeek 一個面向桌面及終端的 AI coding agent,核心價值唔係花巧介面,而係將長會話裡不斷累積的上下文成本壓低。它適合要一路改檔、一路試工具、一路追問模型的人,特別是團隊日常做修補、重構同埋持續迭代時,對 token 成本同回合延遲都會有明顯感受。
Reasonix 主打 cache-first loop,令 prompt 前綴保持 byte-identical,配合 DeepSeek 的 prefix cache 去提升長會話命中率。項目同時提供 CLI/TUI、桌面端、local browser UI,同埋支援 ACP-compatible editor integration,部署方式亦算直接:CLI 可用 npm 安裝,桌面版則有 macOS、Windows、Linux 套件可選。
Deepseek's ~OFFICIAL Code: RIP Claude,Codex! This is CRAZY GOOD!

Reasonix 唔係純粹包住模型嘅殼,而係圍繞工具呼叫修正、成本控制同 sandbox 權限去設計。/plan 會先要求模型規劃,再進入實作;MCP(Model Context Protocol, MCP)亦作為一等入口,方便把外部工具合入同一個 registry。這種做法較適合重視可控性、可追蹤性,亦需要長時間跑 session 的開發流程。
要留意嘅係,呢條 TypeScript 線已經進入 maintenance mode,主力開發搬去 Go rewrite,同步文件亦指向 main-v2 同 migration guide。現時更合理嘅理解方式,係將佢視為一個仍可用但已凍結方向的終端編碼 agent 版本,重點價值在 cache 效率、工具整合與成本壓縮,而唔係追求最新功能擴張。
- 長會話下,prefix cache 命中率可維持在 90%+,輸入 token 成本可明顯下降
- 同一套引擎可喺 CLI/TUI、桌面端、Web UI 同編輯器接入使用
/plan、權限控制同 workspace sandbox 一齊限制工具呼叫,取向偏向可控- 適合經常改碼、反覆驗證、又在意推理成本嘅個人或團隊