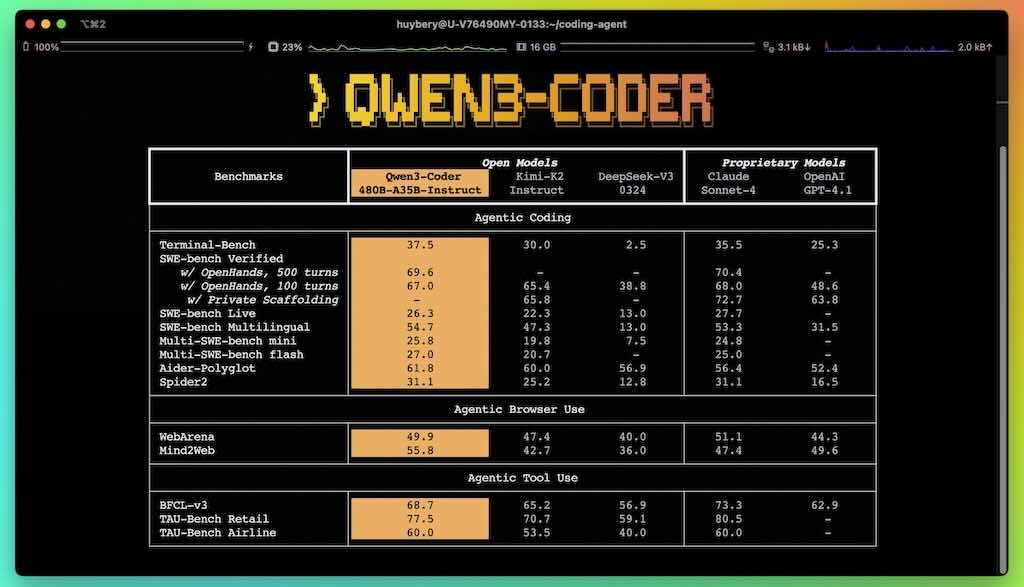
Qwen3-Coder 是我們迄今為止最具代理性的程式碼模型。 Qwen3-Coder 提供多種規模,首先是其最強大的版本:Qwen3-Coder-480B-A35B-Instruct。這是一個擁有 480B 參數的混合專家模型,其中擁有 35B 個有效參數,原生支援 256K 個 token 的上下文長度,並透過外推方法支援 1M 個 token 的上下文長度,在編碼和代理任務中均創下了新的最高紀錄,與 Claude Sonnet 4 相當。
除此,Qwen 開源了一款用於代理程式編碼的命令列工具:Qwen Code。 Qwen Code 是從 Gemini Code 衍生而來,並經過了調整,添加了自訂提示符和函數呼叫協議,從而充分發揮 Qwen3-Coder 在代理程式編碼任務中的強大功能。