VibeVoice 是一個開源,能將文字內容轉化為自然流暢、多角色對話音訊的框架工具。它擁有充滿情感與生命力的聲音。VibeVoice 不僅僅是一個文字轉語音 (TTS) 模型,它更是一個解決傳統 TTS 系統在可擴展性、說話者一致性及自然輪流對話方面重大挑戰的創新框架,特別適用於生成播客等長篇、多說話者的對話音訊。
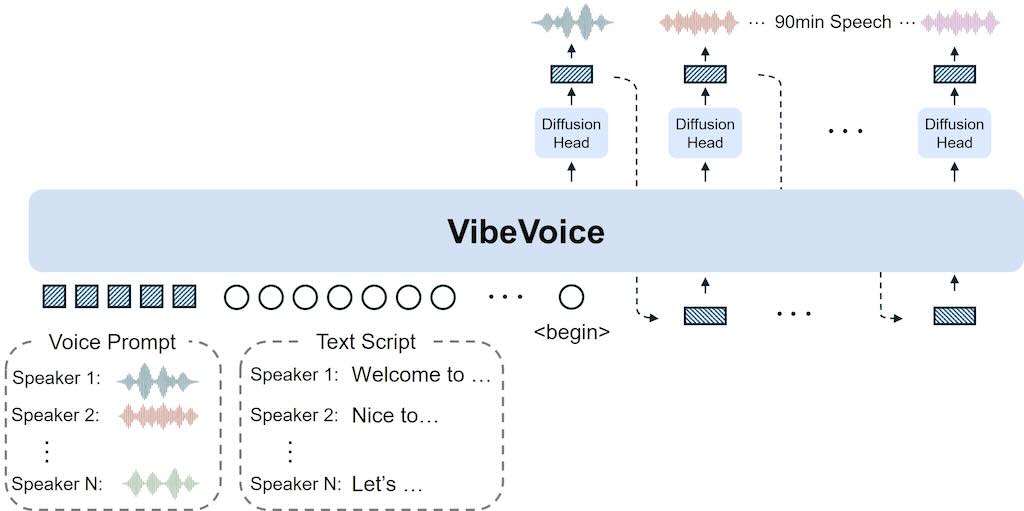
VibeVoice 的核心創新之一,在於其採用了連續語音分詞器(聲學和語義),並以超低 7.5 Hz 的幀率運行。這些分詞器能有效地保留音訊保真度,同時顯著提升處理長序列的計算效率。此外,VibeVoice 採用了「下一詞元擴散」框架,巧妙地利用大型語言模型 (LLM) 來理解文本語境和對話流程,再透過擴散頭生成高保真度的聲學細節。這使得模型能夠合成長達 90 分鐘的語音,並支援多達 4 位不同的說話者,遠超許多先前模型通常僅限於 1-2 位說話者的限制。
(more…)