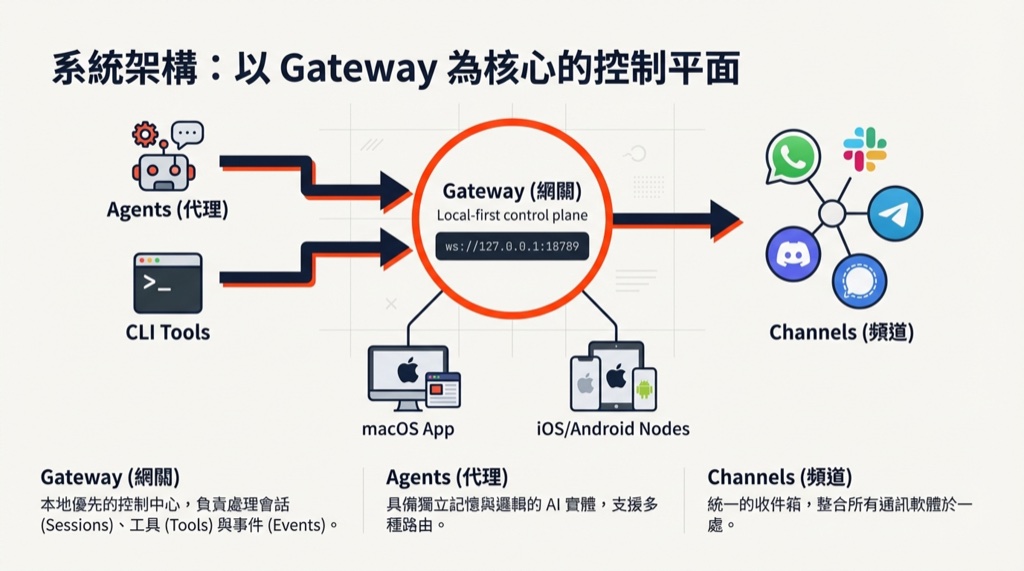
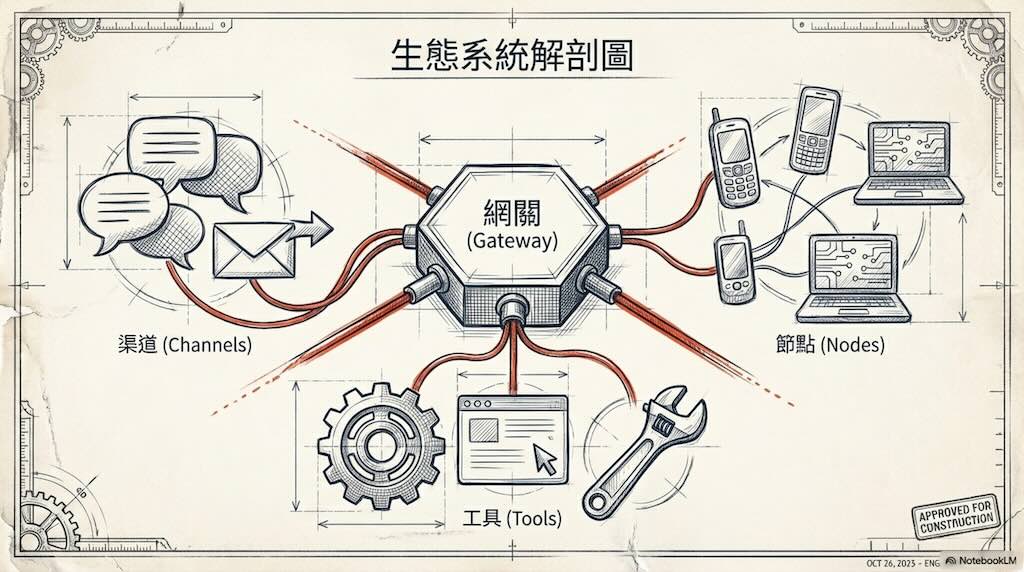
本週,網路上掀起了一股搶購 Mac mini 的熱潮,人們紛紛購買 Mac mini 來運行 Moltbot(原名Clawdbot)。 Moltbot 是一款開源的、可自行託管的AI代理,旨在充當個人助理。
Clawd 誕生於2025年11月-這是「Claude」加上「爪子」的巧妙雙關。一切都完美無缺,直到Anthropic的法務團隊禮貌地要求我們重新考慮。好吧,這很合理。
Moltbot 這個名字是接下來誕生的,它是在凌晨5點與社區成員在 Discord 上進行一場混亂的頭腦風暴後選定的。蛻皮象徵成長-龍蝦脫殼蛻皮,最終長成更大的生物。這個名字寓意深刻,但 念起來卻不太順口。
OpenClaw 就是我們的最終歸宿。這次,我們做了充分的準備:商標檢索結果清晰無誤,網域名稱已購買,遷移程式碼也已編寫完成。
短短48小時內,OpenClaw 在 GitHub 上就獲得了 12.3 萬顆星。彼得·斯坦伯格(Peter Steinberger)的周末計畫一度成為史上成長最快的開源人工智慧工具——直到安全研究人員檢查了其程式碼並發出警報。 OpenClaw 是一款開源的個人人工智慧助手,可在本地運行並連接到 WhatsApp、Slack、Discord和 iMessage 等應用程式。在2026年1月29日至31日期間,OpenClaw從默默無聞一躍成為擁有超過10萬顆星的開源人工智慧助理。開發者們欣喜若狂,終於可以擁有自己的人工智慧助手,而無需再從雲端服務供應商租用。然而,思科和 IBM 的安全專家卻稱之為 “一場噩夢”,並警告稱其存在API金鑰洩漏、提示注入攻擊和企業資料外洩的風險。