CosyVoice-windows-GUI 1.2
Categories: 文字轉語音
DiffSynth-Studio 擴散模型的魔力
本地部署 Flux.1 – Comfyui 一键安装
Llama 3.2 Vision Instruct 詳細的安裝教學
Llama 3.2 Vision Instruct - Installation & Usage Tutorial

DH_live 實時直播數字人
Categories: 軟件
v0 by Vercel 編程 A.I.
SCRAPE ANY WEBSITE with (Llama3.1, Groq, Gemini) (source code included!) – YouTube
Hello Everyone, A lot of you asked about adding a local Llama model to the universal scraper.In this video we’ll see how to use a local free model to scrape …
Create Your LOCAL Llama Web Scraper | Free AI Scraper

Categories: 新聞
Voice AI Assistant to Build JARVIS with Google Gemini
Voice AI Assistant using Python Tutorial | Build JARVIS with Google Gemini

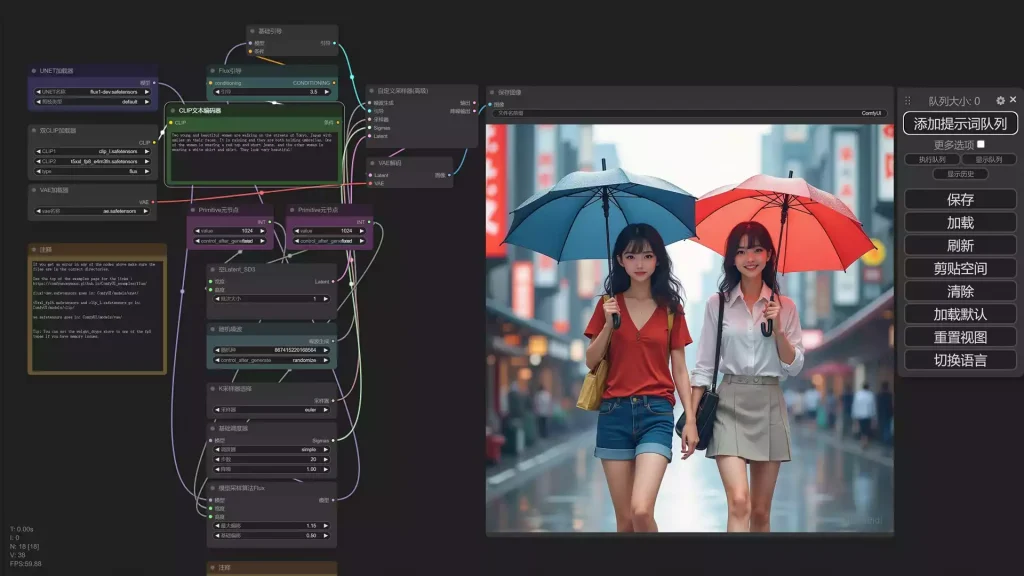
[Flux] Lora 從訓練到放棄

自從 SD3 徹底被放棄之後,Flux 的出現又是一個新的氣象。加上前一陣子 C 站大動作率先支援 Flux Dev 的訓練,所以整個 Flux Lora 如同雨後春筍般瘋狂的冒了出來。 線上工具也是有諸如 AI-toolkit,本地端青龍的訓練包,以及 Kohya。 FLUX 這是由 Block Forest Labs 所釋出的新模型,目前市面上流通的是 Dev 與 Schnell 兩個版本,而 Pro 版本僅只能線上使用並未釋出。這兩個版本都是由 Pro 版本剪支而來(應該是吧?),而 Schnell 則是更精簡的 4 步生成模型。 兩個模型的使用授權範圍不同,Dev 是不可商用的,而 Schnell 基本上走的是 Apache
Categories: 新聞