InfiniDepth 把傳統的深度圖想成一個可以在任何二維座標上即時查詢的隱式場(Implicit Field),而不是固定在像素格子裡。這樣的表示方式讓模型不再受到訓練解析度的限制,能夠直接輸出任意高解析度的深度圖,同時保留更細緻的幾何細節。
NeoVerse 4D 世界模型
NeoVerse 是一種強大的 4D 世界模型,專門設計來處理現實環境中的單眼視頻,從而實現多種應用。這個模型的核心優勢在於它能夠進行無姿態限制的前饋 4D 重建,這意味著它可以從普通的單眼視頻中直接生成高質量的 4D 場景,而不需要複雜的多視角數據或預處理步驟。
DreamID-V 開源換臉
DreamID-V 是一個專門為高保真度臉部交換設計的技術,它旨在縮短圖像到視頻之間的差距。這技術在處理各種挑戰性場景時表現出色,包括頭髮遮擋、複雜光照、多樣化的種族和顯著的臉型變化。DreamID-V 的應用範圍廣泛,可以應用於娛樂、廣告和電影製作等領域,考慮到了實際應用中的多種需求和挑戰。提供更加逼真的臉部交換效果。
對於使用者來說,DreamID-V 提供了單 GPU 和多 GPU 推理的選項,並且有詳細的安裝和使用指南。使用者需要準備好相應的模型文件和依賴庫,然後根據提供的腳本進行操作。此外,DreamID-V 還支持不同的模型版本,例如 DreamID-V-Wan-1.3B-DWPose,這進一步提升了姿態檢測的穩定性和魯棒性。
詳細 Qwen3+RAGFlow 本地部署
【有手就会】20分钟轻松学会搭建本地知识库,全网最详细的Qwen3+RAGFlow本地部署及个人知识库搭建教程,全程干货,零基础也能学会!

Conductor – Google 的 Spec Coding
Conductor 是 Google 推出的一個 Gemini CLI 擴充套件,目前處於預覽階段,它透過「脈絡導向開發」(context-driven development)改變開發流程,讓開發者在編寫程式碼前先建立正式規格與計劃,並將其儲存為持久化的 Markdown 檔案。
Gemini Conductor Full Tutorial For Beginners

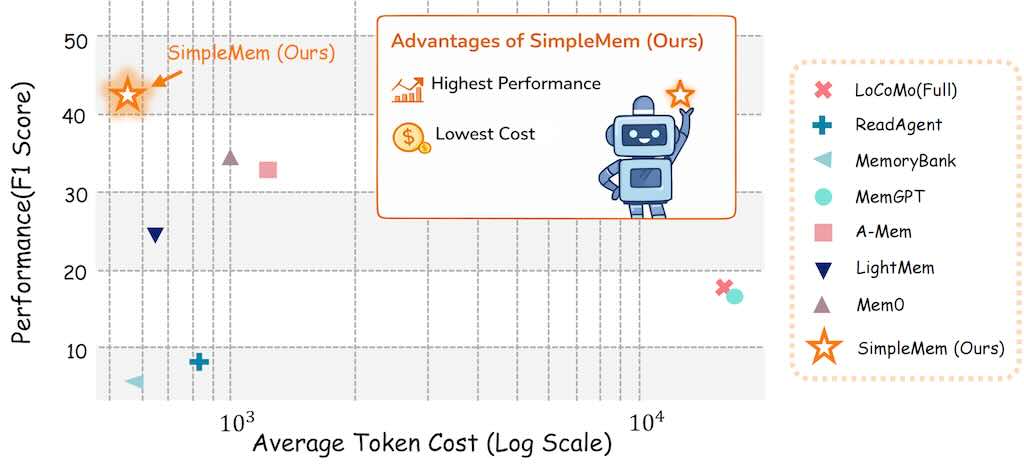
SimpleMem 高效終生記憶框架
端到端小型 LLM 微調教學
示範如何在本地使用 NVIDIA DGX Spark 或 Google Colab 微調 Google 的 Gemma 3 270M 模型,從資料準備到模型部署與 Gradio 示範。
End-to-End (small) LLM Fine-tuning Tutorial (from data to model to live demo)

Google Antigravity 在幾分鐘打造一個完整的 CRM
Google Antigravity 是 Google 推出的新一代 AI 原生 IDE,不是單純聊天寫程式,而是幫你「指揮一整個虛擬工程師團隊」。 在這支影片裡,創作者示範如何用 Antigravity 的 Agent Manager、規劃模式與多 agent 並行,在幾分鐘內從零打造一個完整的 CRM 工具,包含聯絡人、交易 pipeline 和任務管理。
Master 85% of Google Antigravity In 15 Minutes (You'll Be Unstoppable)

透過 Artifacts,你可以像在 Google Docs 一樣對實作計畫、程式碼與螢幕截圖加註留言,人類負責決策與品管,AI 負責大量重工。 更酷的是,Antigravity 內建 Gemini 3 Pro、Claude Sonnet 4.5 和 GPT‑4,讓你可以把 UI 設計、後端架構與日常雜務分配給最擅長的模型來做。 再結合瀏覽器自動化與客製化 Workflow,你等於擁有一個會自己規劃、自己寫、自己測、還會跟你報告進度的超強開發夥伴,現在還是免費就能用的等級。
CoV 提升視覺語言的空間推理能力
CoV (Chain-of-View Prompting for Spatial Reasoning) 可以用於各種需要在複雜三維環境中進行精確空間理解的場景。例如 VR 和 AR,CoV 可以幫助系統更好地理解和響應用戶在虛擬環境中的查詢,提供更自然、更沉浸式的體驗。在自動駕駛領域,CoV 可以增強車輛對周圍環境的理解能力,提高其在複雜道路條件下的導航和決策能力。
CoV 提出一種創新方法,專門針對在三維環境中的具身問答(Embodied Question Answering, EQA)問題。傳統的視覺語言模型(Vision-Language Models, VLMs)受限於固定的輸入視角,這使得它們在推理過程中無法動態地獲取與問題相關的上下文信息,進而限制了複雜空間推理的能力。CoV 通過引入一種免訓練、僅在測試階段運行的框架來解決這一問題,該框架能夠讓 VLMs 變成主動的視角推理器。

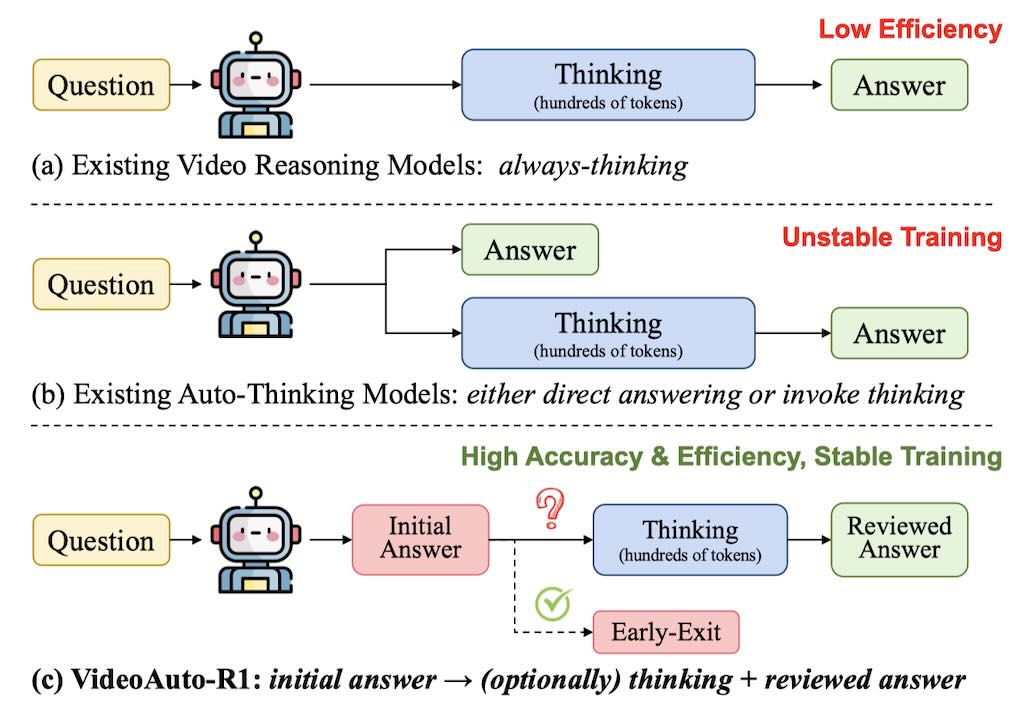
VideoAuto-R1 一次思考,兩次回答視頻推理
VideoAuto-R1 採用了一種「當需要時才推理」的策略。這種策略在訓練階段遵循「一次思考,兩次回答」的範式,即模型首先生成一個初步答案,然後進行推理,最後輸出一個經過審核的答案。這兩個答案都通過可驗的獎勵進行監督。在推理階段,模型使用初步答案的置信度分數來決定是否繼續進行推理過程。Meta 在 VideoAuto-R1 專案中扮演研究合作與工程貢獻角色。
1. 視頻問答系統:VideoAuto-R1 可以應用於各種視頻問答任務,提高系統在理解和回答視頻內容方面的準確性,同時降低計算成本。
2. 教育與培訓:在線教育平台可 leverage 這種技術來提供更智能的學習助手,幫助學生理解複雜的視頻內容,並根據需要提供針對性的解釋。
3. 互動式媒體:增強視頻內容的互動性,例如通過自動推理來回答用戶關於視頻內容的問題。
4. 智能監控:在安全監控系統中,VideoAuto-R1 可以用來分析和解釋監控視頻中的活動,從而提高安全性和監控效率。
5. 自動化客戶服務:在客服領域,該技術可以幫助自動化回答客戶關於產品或服務視頻的問題,提供更個性化的客戶體驗。
6. 內容創作與編輯:視頻創作者可以利用這種技術來自動化地生成視頻描述和解釋,從而簡化內容創作和編輯過程。
7. 多模態學習和研究:VideoAuto-R1 作為一種多模態理解技術,可以促進自然語言處理和電腦視覺領域的研究。
