RAGapp – 整合 Agentic RAG 的最簡單方法
Categories: 工具
Gemini Pro API 嘅一個功能,Add Stop sequence,用嚟控制模型生成文字嘅結果。意思係喺生成文字嗰陣,如果遇到指定嘅意語,就會作出反應。
Add Stop sequence 嘅用法好簡單,應用場景亦非常廣泛,可以有效控制模型嘅生成行為。
以下係一啲例子:
[read more]1. 避免生成重複內
假設我們正在生成一段文本,希望避免生成重複嘅內容。可以將以下序列設定為 Add Stop sequence:
例如,可以將以下內容設定為 Add Stop sequence:
JSON
{
“generateContent”: {
“prompt”: “請生成一段不重複嘅文本”,
“addStopSequences”: [“已經生成嘅詞語或句子”, “特定的關鍵詞或短語”]
}
}
運行模型之後,模型會生成以下文本:
請生成一段不重複嘅文本因為模型遇到咗 “請生成一段不重複嘅文本” 嘅序列,所以停止咗生成。
2. 控制生成長度
假設我們正在生成一段文本,希望控制生成嘅長度。可以將以下序列設定為 Add Stop sequence:
例如,可以將以下內容設定為 Add Stop sequence:
JSON
{
“generateContent”: {
“prompt”: “請生成一段長度為 100 個字符嘅文本”,
“addStopSequences”: [“100 個字符”, “.”]
}
}
請生成一段長度為 100 個字符嘅文本執行呢個 Prompt 之後,模型會生成以下文本:
因為模型遇到咗 “.” 嘅序列,所以停止咗生成。
3. 定制生成格式
假設我們正在生成一段文本,希望控制生成嘅格式。可以將以下序列設定為 Add Stop sequence:
例如,可以將以下內容設定為 Add Stop sequence:
JSON
{
“generateContent”: {
“prompt”: “請生成一段 HTML 格式嘅文本”,
“addStopSequences”: [“</body>”, “</html>”]
}
}
運行模型之後,模型會生成以下文本:
HTML
<!DOCTYPE html>
<html>
<head>
<title>示例</title>
</head>
<body>
請生成一段 HTML 格式嘅文本
</body>
</html>
因為模型遇到咗 “</body>” 嘅序列,所以停止咗生成。
4. 實現特定功能
假設我們正在生成一段文本,希望實現特定嘅功能。可以將以下序列設定為 Add Stop sequence:
例如,可以將以下內容設定為 Add Stop sequence:
JSON
{
“generateContent”: {
“prompt”: “請生成一段可以回答問題嘅文本”,
“addStopSequences”: [“?”, “## 答案”]
}
}
運行模型之後,用戶可以向模型提出問題。模型會生成以下文本:
問題:臺灣中國有哪些適合旅遊的景點?
## 答案
臺灣有許多適合旅遊的景點,以下是一些例子:
* 台北:臺灣的首都,擁有許多歷史古蹟和現代建築。
* 高雄:臺灣的第二大城市,擁有美麗的海灘和繁華的夜市。
* 台中:臺灣的中部城市,擁有豐富的自然景觀和人文風情。
* 台南:臺灣的古都,擁有許多傳統文化遺產。
* 花蓮:臺灣東部的城市,擁有壯麗的峽谷和海岸線。
* 臺東:臺灣南部的城市,擁有豐富的原住民文化。
臺灣的四季分明,適合不同季節的旅遊。春、秋兩季氣候宜人,是旅遊的最佳季節。夏、冬兩季氣候較為極端,但也有其獨特的魅力。
臺灣的交通十分便利,有飛機、高鐵、巴士等多種交通方式可供選擇。臺灣的住宿設施也十分齊全,有酒店、民宿、青年旅社等多種選擇。
臺灣的人民熱情好客,樂於助人。臺灣的治安良好,是旅遊的理想目的地。
[/read]

使用自然語言或程式碼優先的方法建立 AI 虛擬服務專員。運用一系列的選項,輕鬆連結虛擬服務專員與企業資料。Vertex AI Agent Builder 是 Vertex AI Search and Conversation 的擴充及品牌重塑版本。
Golden RAGtriever 是一款開源應用程序,旨在為開箱即用的檢索增強生成 (RAG) 提供端到端、簡化且用戶友好的介面。只需幾個簡單的步驟,即可在本地透過 HuggingFace 和 Ollama 或透過 OpenAI、Cohere 和 Google 等 LLM 供應商探索您的資料集並輕鬆提取見解。


展示如何在 Stable Diffusion Modal 上開發 ComfyUI 工作流程以及如何將該工作流程轉換到可擴展的 API 端點。
作者於 2024 年 5 月 16 日 更新,以反映 ComfyUI 範例的最新更新。
影片示範如何使用 Langchain RAG fusion 和 GPT-40 為您的 PDF 創建人工智能的代理聊天機器人,供您個人或商業使用。影片包含用於設置檢索增強生成系統的 Python 代碼演練。

Rag Fusion 是一種通過多查詢方法克服傳統搜索系統限制的方法,從而改善性能。
GPT-40 是 2024 年 5 月 14 日宣佈的 GPT-4 Turbo 的更高端模型。它可以處理文本、圖像和語音輸入。
影片重點介紹檢索增強生成 (RAG) 的運作方式以及 GPT-40 的功能。
核心概念是從原始查詢生成多個查詢,然後重新排序每個查詢的搜索結果,並提取具有高度相關性的結果。
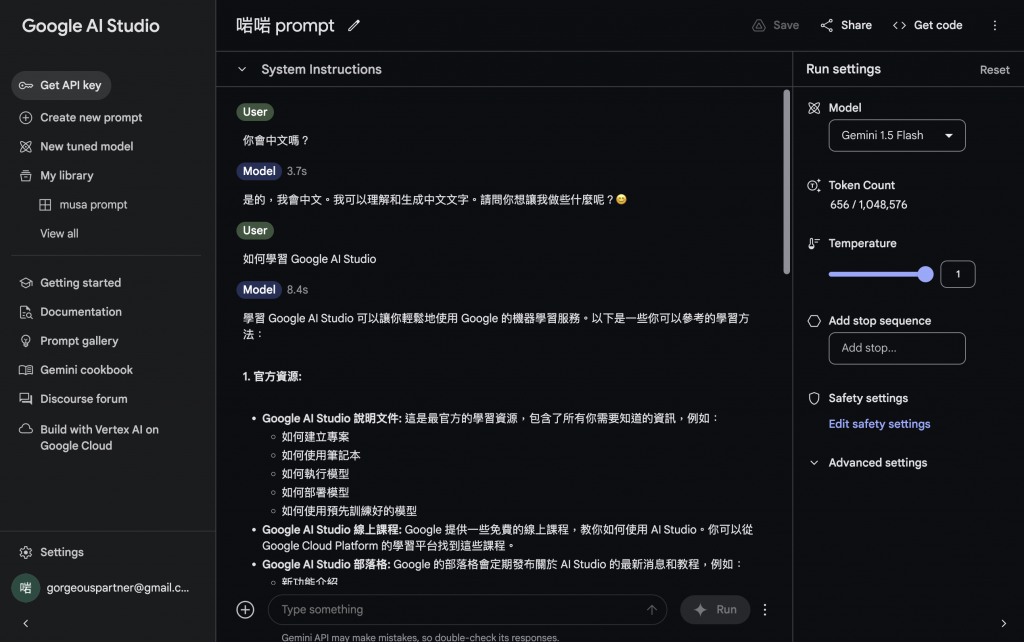
Google AI Studio 是一個由 Google AI 開發的雲端平台,可讓您使用 Gemini 多模態生成式 AI 模型來創建各種內容。Gemini 是一個強大的 AI 模型,可以生成文字、程式碼、圖像、音樂等。Google AI Studio 使您可以輕鬆使用 Gemini,而無需任何編碼或機器學習知識。
Google AI Studio 仍處於早期開發階段,但它已經可以用於許多目的,例如:
Google AI Studio 的一些功能包括:
如果您有興趣嘗試使用 AI 來激發您的創意,那麼 Google AI Studio 值得一試。
A.I. 不斷普及,可能越嚟越多技術名稱令人莫明費解。這兩條影片可能會令你更徹底了解 A.I. 是如何運作。