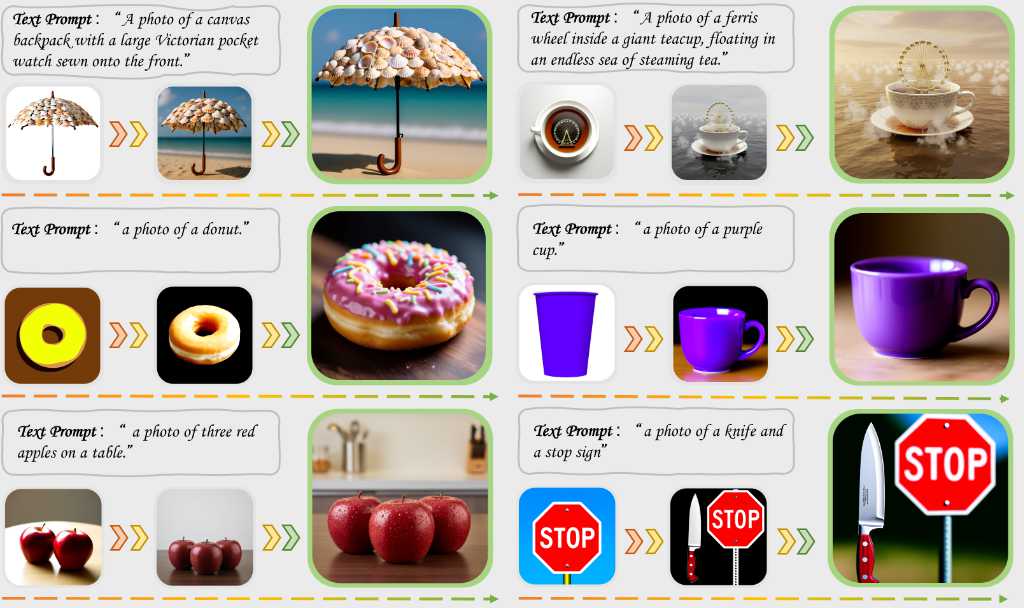
PersonaPlex 是一款即時、全雙工的語音對話模型,它透過基於文字的角色提示和基於音訊的語音訓練來實現角色控制。該模型結合了合成對話和真實對話進行訓練,能夠產生自然、低延遲且角色一致的語音互動。 PersonaPlex 是基於 Moshi 架構和權重。
NVIDIA PersonaPlex: Natural Conversational AI With Any Role and Voice

PersonaPlex 是一款即時、全雙工的語音對話模型,它透過基於文字的角色提示和基於音訊的語音訓練來實現角色控制。該模型結合了合成對話和真實對話進行訓練,能夠產生自然、低延遲且角色一致的語音互動。 PersonaPlex 是基於 Moshi 架構和權重。
GLM-4.7-Flash 是 Zhipu AI 最新發布的 30B 參數 MoE 模型(3B 活躍參數),專為高效本地運行與程式碼生成設計,在同尺寸模型中達到開源 SOTA 效能。
影片使用 Inferencer app 在 M3 Ultra Mac Studio (512GB RAM) 測試 GLM-4.7-Flash 的 MLX 量化版本,比較未量化與 Q4/Q5/Q6/Q8 效能。未量化版生成 5000 個 token 的 3D 太陽系程式(含滑鼠互動),優於 Qwen3-Coder 30B (1700 token) 與 Neotron。
量化後 Q5/Q6 版維持高品質輸出(56 token/s,24-27GB 記憶體),適合 32GB 系統;批次處理 4 個提示達 120 token/s 總吞吐量,但記憶體升至 140GB。量化指標顯示 Q6 perplexity 1.23、token accuracy 96.65%,僅輕微發散,證明品質接近基模。

| 量化級別 | Perplexity | Token Accuracy | 記憶體使用 (GB) | Token/s (單一批次) |
|---|---|---|---|---|
| Base | 1.22 | 100% | 60 | – |
| Q5.5 | 1.25 | 94.5% | 24 | 56 |
| Q6.5 | 1.23 | 96.7% | 27 | 56 |
| Q8.5 | 1.23 | 97.8% | 34 | 50 |
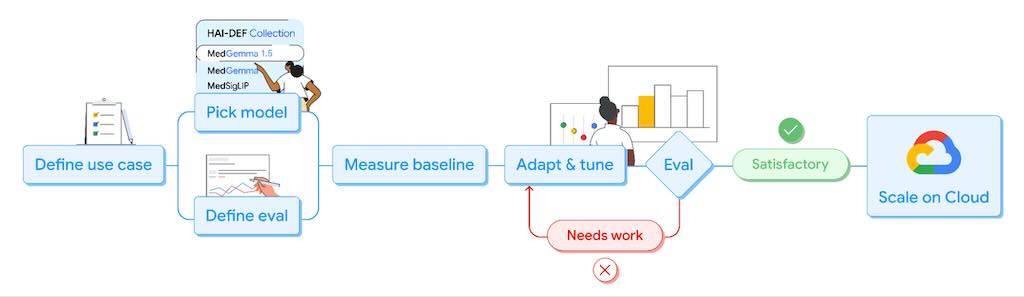
人工智慧在醫療保健領域的應用正以驚人的速度加速發展,其應用速度是整體經濟的兩倍。為了支持這項變革,Google去年透過其健康人工智慧開發者基金會(HAI-DEF) 計畫發布了 MedGemma 開源醫療生成式人工智慧模型集。 MedGemma 等 HAI-DEF 模型旨在為開發者提供評估和調整的起點,以適應其醫療應用場景,並且可以
透過 Vertex AI 在Google雲端 上輕鬆擴展。 MedGemma 的發布反應熱烈,下載量達數百萬次,並
在 Hugging Face 上發布了數百個社區構建的變體。
ShapeR 是以 rectified‑flow 為基礎的生成模型,能直接從日常拍攝的影像序列(即「不規則」捕捉)重建高保真的三維物件。整體流程大致可以分成幾個步驟:
先用現成的視覺‑慣性 SLAM 演算法把鏡頭移動和稀疏點雲拿出來,接著再交給 3D 物件偵測器把每個目標物分割出來。每個偵測到的物件會得到幾張具備相機位姿的多視角圖片、一組稀疏的 SLAM 點,還有一段由視覺語言模型自動產生的文字說明。這些資訊(點雲、多視圖、文字)會被封裝成一個多模态的條件向量,送給訓練好的 rectified‑flow Transformer 去去噪。
Transfomer 輸出的 latent VecSet 接著經過一個 3D VAE 解碼,最後生成完整的三維網格。整個模型只需要在合成資料上先做大量的單物件預訓練,接著再在更具挑戰性的合成場景與真實場景資料上進行兩階段的訓練,過程中會不斷加入各種自然的背景、遮擋、噪聲以及 augmentations,讓模型學會在「雜亂」的環境下仍保持穩定。
研究團隊也釋出了一個專屬的評估資料集:裡面有 178 個真實世界的物件分布在七個場景中,配有完整的地面真值網格、配對好的多視圖影像、SLAM 點雲與文字描述。這筆資料專門用來測試在野外捕捉時的遮擋、雜亂、解析度變化等情況,讓模型在更貼近實務的條件下接受測試。
在測試結果上,ShapeR 在 Chamfer Distance 指標上比目前最好的方法提升了 2.7 倍,顯示出在「不規則」情境下的穩定性確實比先前的單視圖或全局場景重建方式更佳。相較於同樣流行的 SAM3D 方法,ShapeR 的特色在於它利用多視圖的幾何資訊(SLAM 點、相機位姿)來保證形狀的尺度與真實感,而 SAM3D 則依賴單張圖像與互動,對於規模和視角的一致性較弱。兩者其實可以互補——把 ShapeR 的幾何結果再送給 SAM3D 生成更豐富的材質或細節。
總結來說,ShapeR 透過把 SLAM 點雲、3D 偵測、多視圖影像和自動文字說明這幾種資訊全部結合起來,做出一個能在日常拍攝場景下產生高品質、具備度量真實性的單物件三維形狀的生成模型,並提供了完整的測試素材與模型資源讓研究者直接使用。

| 面向 | ShapeR | SAM3D |
|---|---|---|
| 輸入 | 多視角序列 + SLAM 點 + caption 等多模態 | 單張影像 +(物件時多半要 mask / 互動) |
| 任務重點 | 場景級、物件為中心的度量重建與佈局 | 單視圖高品質幾何 + 貼圖的物體/人體重建 |
| 幾何精度 | 強調 metric accuracy、相對尺度與佈局一致性 | 可缺乏精確比例與 layout,特別是複雜場景 |
| 紋理 / 外觀 | 較偏幾何與場景結構(官網重點在 shape) | 強調 photoreal 紋理與真實外觀 priors |
| 互動需求 | 不需要使用者互動,pipeline 自動處理 | 需要物件 mask / prompt,屬於 promptable / interactive workflow |
| 訓練數據 | 合成多模態場景(SLAM + 多視圖) | 大規模真實 image→3D(Objects/Body 各自的 dataset) |
| 適合場景 | AR 眼鏡 / 機器人多視角感知、場景 mapping、學術評測 | 商業應用:電商 AR、human pose & shape、單圖 3D content creation |
FrankenMotion 是一個以擴散模型為基礎的文本到人體動作生成框架,專注於對單一動作的各個身體部位進行細緻控制。研究團隊先建立名為「FrankenStein」的大規模運動資料集,這份資料集以大型語言模型自動生成的原子化、具備時間感知的逐部份文字敘述,填補了先前資料集只能提供全局或動作層級標註的不足。透過這些高度結構化的部位標註,模型能夠在訓練時同時學習空間(哪個部位在動)與時間(每個部位的具體時間模式)兩層資訊。
實驗結果顯示,相較於先前的 UniMotion、DART、STMC 等模型,FrankenMotion 在語義正確性與運動真實感上都有顯著提升,甚至能創造出訓練時未曾見過的組合動作,例如在坐下的同時抬起左手。
Google 推出 TranslateGemma,這是一套基於 Gemma 3 構建的全新開放式翻譯模型,提供 4B、12B 和 27B 三種參數規模。它標誌著開放式翻譯領域向前邁出了重要一步,能夠幫助人們跨越 55 種語言進行交流,無論他們身處何地,使用何種設備。
TranslateGemma 含 55 種語言的 WMT24++ 資料集上測試了 TranslateGemma 模型,該資料集涵蓋了多種語言體系,包括高資源、中資源和低資源語言。與基準 Gemma 模型相比,TranslateGemma 在所有語言中均顯著降低了錯誤率,在提高翻譯品質的同時實現了更高的效率。
agent-browser 專注於為 AI Agent 提供快速、可靠的瀏覽功能。整個專案使用 Rust 撰寫核心腳本,提供高效的執行速度,同時保留 Node.js 作為後備方案,讓開發者可以在不同環境下自由切換。

HeartMuLa 是個完全開放 source 的音樂基礎模型家族,整個系統把四個核心功能結合在一起:首先是 HeartCLAP,負責把音樂和文字換位成共享的嵌入空間,讓系統能夠精準地把音樂標籤對應到文字敘述,並支援跨模式檢索。接下來是 HeartTranscriptor,專門用來在實際音樂裡捕捉歌詞,即使在背景噪音或複雜編曲之下也能保持較低的錯字率。第三個組件是 HeartCodec,它以極低的頻率(每秒 12.5 次)進行音訊壓縮,卻仍保留細節,使得長篇音樂能夠在解壓時恢復高保真度,同時提供緊湊的離散表示,方便後續的 autoregressive 生成。最後是 HeartMuLa 本身,這是一個以大型語言模型為基礎的歌曲生成模型,接受使用者提供的文字風格描述、完整歌詞甚至參考音頻作為條件,並能在多種可控制維度上操作,例如指定段落的流派、情緒、節奏或其他音樂特徵。

它還提供兩個特別模式:一種適合當作短視訊背景音的快速生成,另一種則可以在全曲長度(最長可達六分鐘)上維持結構連貫性與風格多樣性,並允許使用者針對不同段落(如主歌、副歌)輸入自然語言指令,精細調整音樂風格。
Step3-VL-10B 是一款輕量級開源基礎模型,旨在重新定義緊湊高效與前沿多模態智能之間的權衡。儘管僅有 10B 參數,Step3-VL-10B 在視覺感知、複雜推理和人類對齊方面表現卓越。
該模型在 10B 規模以下的模型中始終表現最優,並能媲美甚至超越規模大 10×–20× 的開源模型(如 GLM-4.6V 106B-A12B、Qwen3-VL-Thinking 235B-A22B)以及頂級閉源旗艦模型(如 Gemini 2.5 Pro、Seed-1.5-VL)。
Demo: 根據表格推導”STEPFUN”的莫爾斯編碼

Thinking Process
用户现在需要把每个字母转换成莫尔斯电码,先看每个字母在表中的编码。首先分解"STEPFUN"每个字母:S、T、E、P、F、U、N。
S:看右边第三列第一个,S是···(三个点)。(一个短横)
T:第三列第二个,T是-。
E:左边第一列第五个,E是·(一个点)。
P:中间列(J到R)中P对应的符号是·--·点、短横、短横、点)。
F:最左侧列第六行,F的符号是··-·(两个点、一个短横、一个点)。
U:最右侧列第三行,U的符号是··-(两个点、一个短横)。
N:中间列(J到R)第五行,N的符号是-·一个短横、一个点)。
再将每个字母的编码按顺序拼接(字母间用空格分隔更清晰),"STEPFUN"的莫尔斯电码为:··· - · ·--· ··-· ··- -·
Final Answer
··· - · ·--· ··-· ··- -·Step3-VL-10B 的成功源於兩大核心設計:高質量多模態語料庫的統一預訓練(1.2T tokens)與規模化多模態強化學習(超過 1,400 次 RL 迭代),並引入 Parallel Coordinated Reasoning (PaCoRe) 實現並行視覺探索的證據聚合。