Sim(由Sim Studio開發)是一款開源的AI代理工作流程建構工具,提供輕量且直觀的使用介面,讓開發者能便捷快速地建立、測試及部署結合大型語言模型(LLMs)與其他工具的智能代理系統。
Install Sim Locally with Ollama: AI Agent Workflow Builder

Sim(由Sim Studio開發)是一款開源的AI代理工作流程建構工具,提供輕量且直觀的使用介面,讓開發者能便捷快速地建立、測試及部署結合大型語言模型(LLMs)與其他工具的智能代理系統。
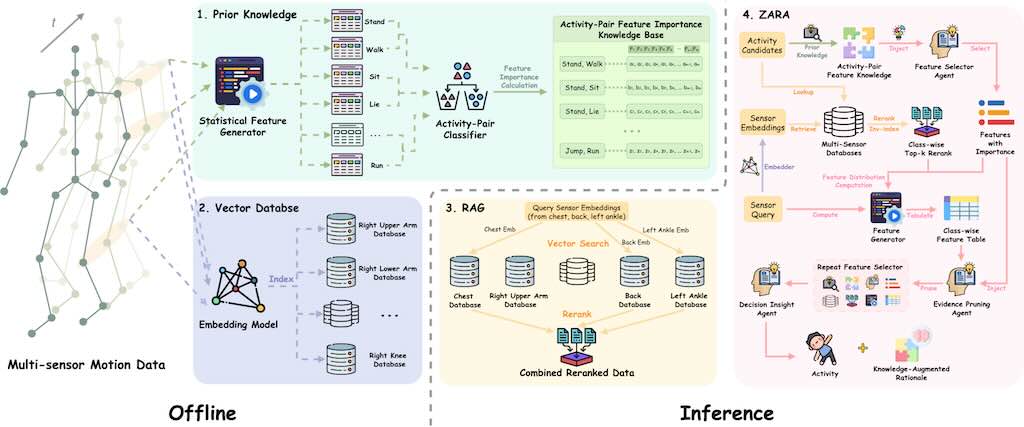
ZARA 是一個用於人類身體活動識別 (HAR Human Activity Recognition) 的新型框架,它利用穿戴式感測器的原始運動數據。傳統的 HAR 系統通常需要針對特定任務的深度學習模型進行昂貴的重新訓練,而且在引入新感測器或未見活動時,其泛化能力和零樣本識別能力有限,同時也缺乏可解釋性。
ZARA 透過結合多感測器檢索增強生成 (RAG)、自動化的成對領域知識注入和層次代理式大型語言模型 (LLM) 推理來克服這些限制。ZARA 不需額外訓練,就能在多種數據集和感測器配置上實現零樣本分類,其性能超越現有方法,並可提供驗證。研究強調了其檢索、知識庫和代理模組在提升準確性和支援決策方面的關鍵作用。
LIA-X (Interpretable Latent Portrait Animator)強調其控制性,適合 AI 研究者和內容創作者使用,旨在將臉部動態從驅動影片遷移到指定的頭像,並實現精細控制。
LIA-X 的可解釋性與細粒度控制能力,使其支援多種實際應用:
LongSplat 是個用於從隨機拍攝的長影片中生成新穎視角的三維高斯噴灑(3D Gaussian Splatting)框架。它能夠解決從隨機拍攝、具有不規則攝影機運動和未知攝影機姿態的長影片中進行新視角合成的關鍵挑戰。
Qwen-Image-Edit 是 Qwen-Image 的圖像編輯版本,基於20B模型進一步訓練,支持精准文字編輯和語義/外觀雙重編輯能力。它具備多項關鍵功能與技術優勢:

影片展示了如何利用 FastRTC 建立一個免費且本地運行的語音 AI 代理。這個系統的關鍵優勢在於它無需昂貴的 GPU 即可在 CPU 上運行,並確保使用者資料的 100% 私密性。它結合了 FastRTC 作為即時通訊庫、Gemma 作為語言模型 (LLM) 和 Coqui 作為文本轉語音 (TTS) 引擎,全部皆為開源工具。儘管存在回應延遲和語音自然度等局限性,但此設定在隱私性、成本效益和易用性方面表現出色,尤其適用於語言練習、互動式日記和講故事等不需要即時回應的應用場景。

傳統的卡通/動漫製作耗時耗力,需要技藝精湛的藝術家進行關鍵影格、中間畫和上色。 ToonComposer 利用生成式 AI 簡化了這個流程,將數小時的中間畫和上色手動工作簡化為一個無縫銜接的流程。

用於音訊驅動頭像視訊產生的擴散模型難以合成具有自然音訊同步和身份一致性的長視訊。基於 Wan2.1-1.3B 的 StableAvatar 音訊驅動的頭像視訊效果,是首個端到端視訊擴散變換器,無需後製即可合成無限長的高品質視訊。
FantasyPortrait 支援使用多個單人影片或單一多人影片驅動多個角色,產生細緻的表情和逼真的肖像動畫。
從靜態圖像中製作富有表現力的臉部動畫是一項極具挑戰性的任務。現有方法缺乏對多角色動畫的支持,因為不同個體的驅動特徵經常相互幹擾,使任務變得複雜。FantasyPortrait 提出了 Multi-Expr 資料集和 ExprBench,它們是專門為訓練和評估多角色肖像動畫而設計的資料集和基準。大量實驗表明,FantasyPortrait 在定量指標和定性評估方面均顯著超越了最先進的方法,尤其是在具有挑戰性的交叉重現和多角色情境中表現出色。

