Ray 3: The First Reasoning Video AI (HDR, Physics, Consistency)

開源 Cosmos DiffusionRenderer 是一個視訊擴散框架,用於高品質影像和視訊的去光和重光。它是原始
DiffusionRenderer 的重大更新,在 NVIDIA 改進的資料管理流程的支持下,實現了顯著更高品質的結果。
最低要求 Python 3.10 NVIDIA GPU 至少配備 16GB VRAM,建議配備 >=48GB VRAM NVIDIA 驅動程式和 CUDA 12.0 或更高版本 至少 70GB 可用磁碟空間

教學:



Spec Kit 是一個由 GitHub 開發並開源的工具包,旨在透過 規範導向開發(Spec-Driven Development) 來幫助開發者更快速地建構高品質的軟體。
這套工具顛覆了傳統的開發模式,將規格文件從靜態的藍圖轉變為可執行的程式碼。它以用戶或產品的意圖為核心,利用了先進的 AI 模型建立清晰且詳細的規格,步優化和完善開發流程,最後直接生成可運作的軟體。
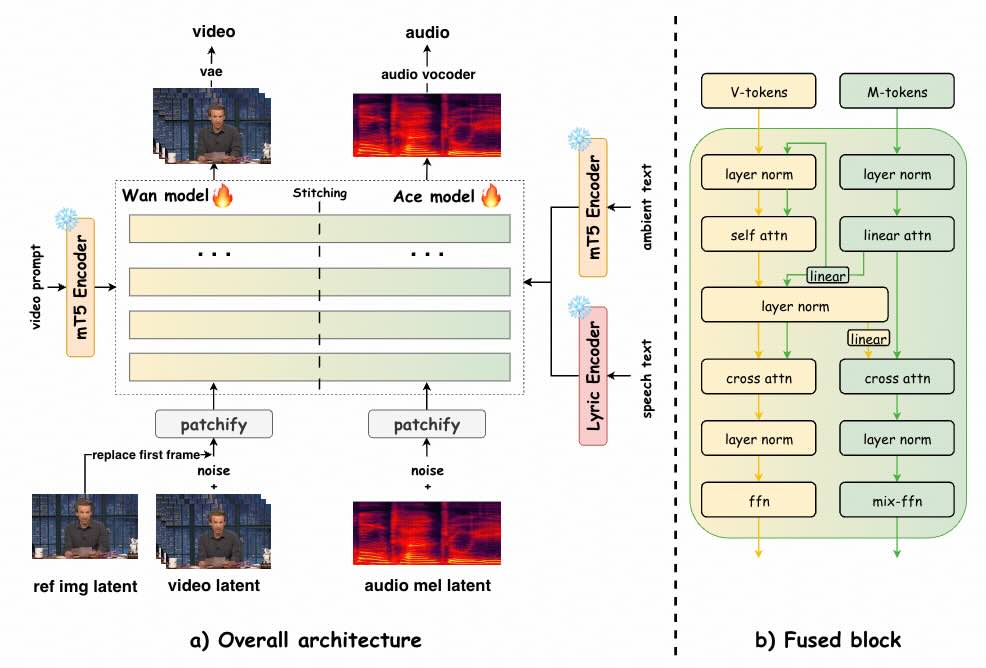
UniVerse-1 是個類似 Veo-3 的模型,可根據參考圖像和文字提示同時產生同步音訊和視訊。
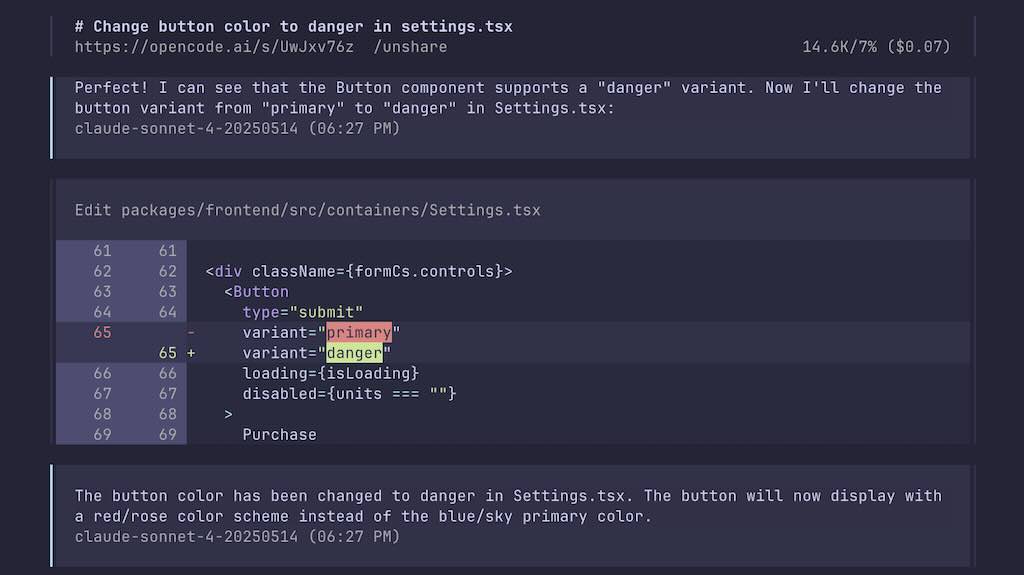
opencode 是一個基於終端機的 AI 工具,專注於協助開發者在終端機環境中進行編碼、除錯等任務。它提供了一個互動式的終端使用者介面(TUI),並支援多種 AI 模型和語言伺服器協議(LSP),以提供程式碼智能功能。
不同於其他工具(如 Claude Code),opencode 不依賴特定 AI 提供商,支援超過 75 個大型語言模型(LLM)提供商,包括 OpenAI、Anthropic Claude、Google Gemini、AWS Bedrock、Groq、Azure OpenAI 等,甚至支援本地模型。
DeepCode 是個 AI 驅動的開發平台,可自動執行程式碼產生和實作任務。我們的多代理系統能夠處理將需求轉化為功能齊全、結構良好的程式碼的複雜性,讓您專注於創新,而不是實現細節。
DeepCode 透過為常見的開發任務提供可靠的自動化來解決這些工作流程效率低下的問題,從而簡化從概念到程式碼的開發工作流程。
https://github.com/HKUDS/DeepCode

模型上下文協定 (MCP) 伺服器為 AI 輔助軟體開發提供結構化的規範驅動的開發工作流程工具,具有即時 Web 儀表板和 VSCode 擴展,可直接在開發環境中監控和管理專案進度。
https://github.com/Pimzino/spec-workflow-mcp

Sim Studio 是個輕量、直觀的開源項目及平台,專注於建構和部署基於大型語言模型(LLM)的 AI 代理工作流程。其核心目標是簡化複雜的 AI 代理開發過程,特別是多步驟代理系統的設計與調試。Sim 提供了一個用戶友好的界面,允許開發者通過拖放式工作流程快速構建和整合 AI 功能,並與多種工具(如 GitHub)進行無縫連接。

它提供雲端託管選項(可在 https://sim.ai 使用),以及多種自託管方式,包括 NPM 套件、Docker Compose、Dev Containers 和手動設定。平台支援使用 Ollama 運行本地 AI 模型(可選擇 GPU 或 CPU),並利用向量嵌入來實現知識庫和語義搜尋等功能。開發環境主要基於 JavaScript 運行時 Bun,並需配置 PostgreSQL 資料庫(含 pgvector 擴充)。
