【有手就会】20分钟轻松学会搭建本地知识库,全网最详细的Qwen3+RAGFlow本地部署及个人知识库搭建教程,全程干货,零基础也能学会!

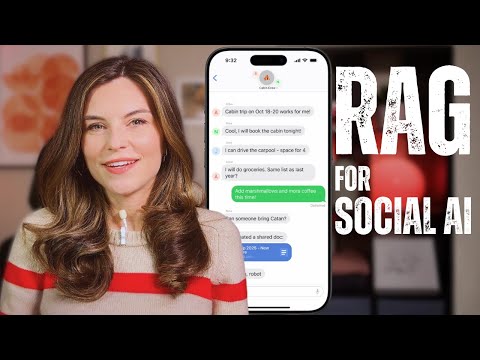
在 RAG(檢索增強生成,Retrieval-Augmented Generation)流程中融合 HyDE 技術,特別是在社交群組 AI 助理的應用場景。影片詳細說明了 RAG 的基本原理、技術演進、現實挑戰,以及 HyDE 方法如何解決多輪群聊語意檢索問題、具體提升個人化推薦的效果。
這案例對 RAG 技術實戰落地非常有啟發,尤其在社群、記憶建構、個人化需求場景的處理方式。若你有自己的群聊 AI 專案,這種查詢增強流程、高維語意檢索建議、如何平衡效率與準確,是值得深入借鑑的。
ZARA 是一個用於人類身體活動識別 (HAR Human Activity Recognition) 的新型框架,它利用穿戴式感測器的原始運動數據。傳統的 HAR 系統通常需要針對特定任務的深度學習模型進行昂貴的重新訓練,而且在引入新感測器或未見活動時,其泛化能力和零樣本識別能力有限,同時也缺乏可解釋性。
ZARA 透過結合多感測器檢索增強生成 (RAG)、自動化的成對領域知識注入和層次代理式大型語言模型 (LLM) 推理來克服這些限制。ZARA 不需額外訓練,就能在多種數據集和感測器配置上實現零樣本分類,其性能超越現有方法,並可提供驗證。研究強調了其檢索、知識庫和代理模組在提升準確性和支援決策方面的關鍵作用。
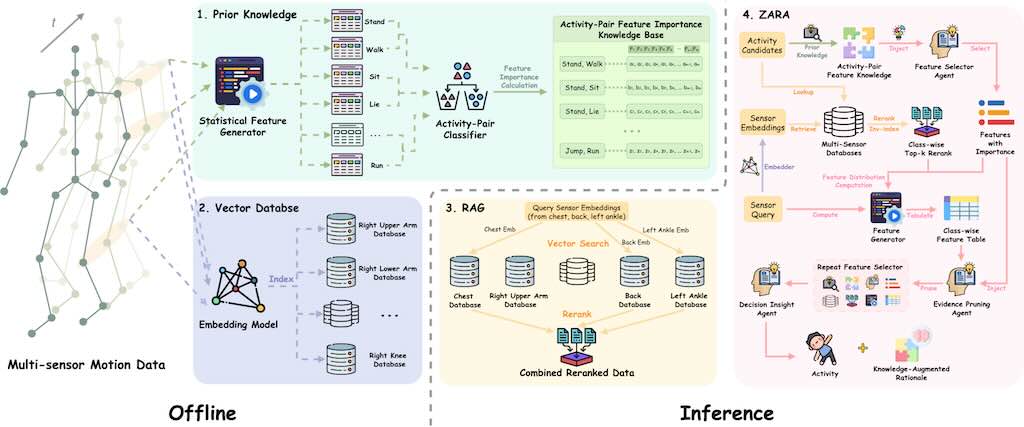

影片中,作者使用了 Google 的 embedding 模型和 ChromaDB 向量資料庫來實現這個架構。
影片強調動手實作的重要性,鼓勵觀眾親自寫一遍程式碼以加深理解。

影片介紹如何用 LangGraph、Agentic RAG、Nano-GraphRAG 和 Claude 3.7 Sonnet 製作一個具備推理能力的代理 Agent。作者透過展示了使用不同的工具,令 AI 模型能夠使用計算機、字典和搜尋引擎來增強 AI 模型的能力。

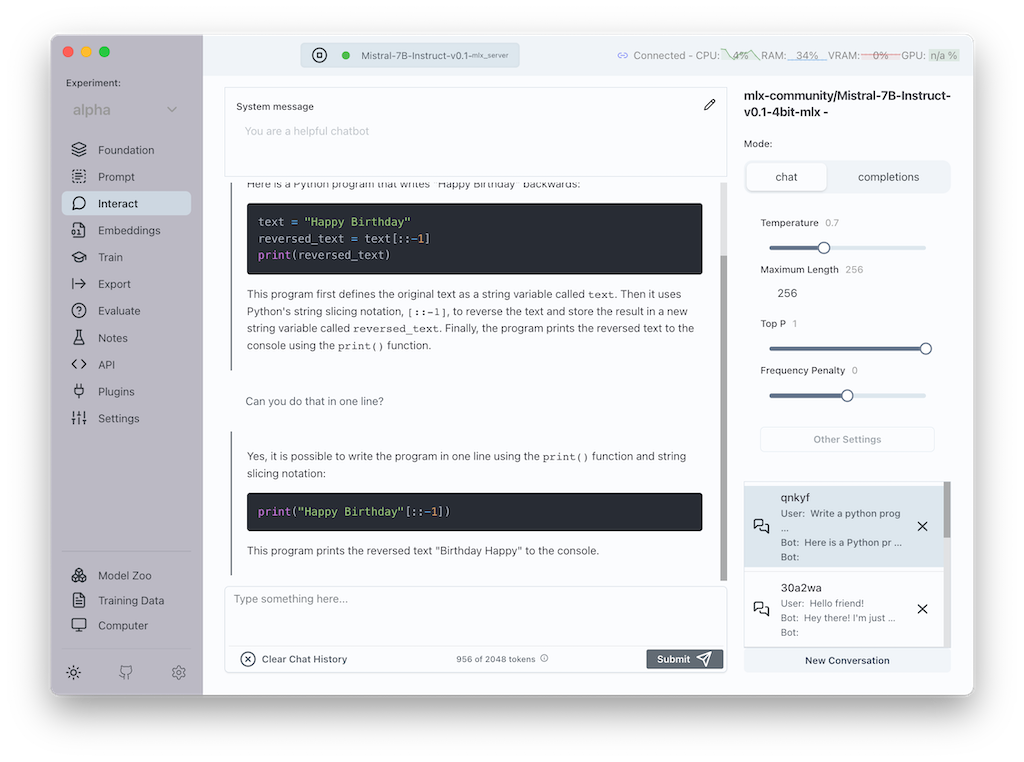
Transformer Lab 是個免費的開源 LLM 工作平台,方便進行微調、評估、匯出和測試,並支援唔同的推理引擎和平台。Transformer Lab 適用於擁有 GPU 或 TPU 的電腦,亦支援 MLX 的 M 系列的蘋果電腦。主要功能包括下載開源模型、智能聊天、計算嵌入、創建和下載訓練數據集、微調和訓練 LLM、以及使用 R A G 與文件互動。

![]()
影片教你如何建立一個簡單的 Web 應用程式,使用 Ollama LangChain 和 Gradio,透過檢索增強生成 (RAG) 來查詢 PDF 文件。無論你是 AI 的初學者或已有經驗,只要有興趣用 Web 運行 AI 模型,這教學都非常實用。由於支持離線運作,因此能夠增加安全性,保障私隱,特別是對於使用 AI 處理公司內部文件嘅任務。

利用 Gemini 2.0 的多模態即時 API 來建立一個實時的語音 RAG 助手。RAG,也就是檢索增強生成,肯定是語言模型中最有價值的增強之一。透過上下文感知的回答,它被證明是處理有關最新資訊的問題或任務的有效方法。
由於 Gemini 的多模態即時 API 裡面沒有內建的文件檢索介面,影片將展示如何建立一個自訂的流程,來接收用戶的語音,從提供的文件中檢索內容,然後讓Gemini 以語音回覆。

