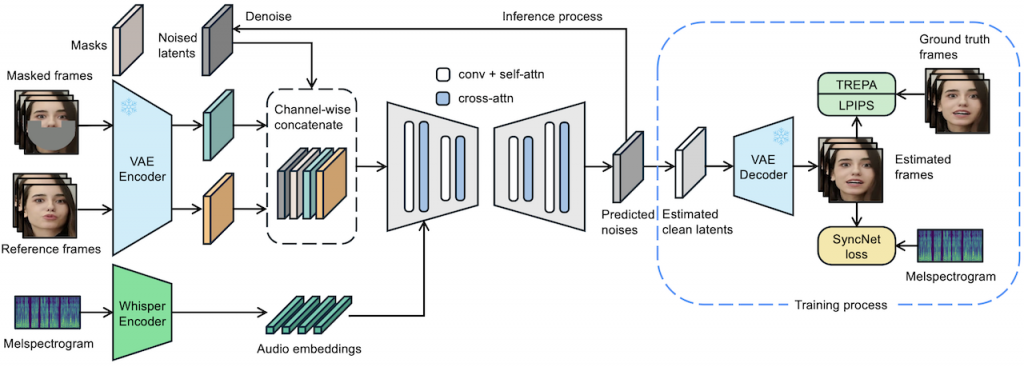
Train a Qwen-Image LoRA on 24GB VRAM With AI Toolkit

影片主要介紹如何使用 Ostris AI 開發的 AI Toolkit,在僅有 24 GB VRAM 的 RTX 4090 或 3090 GPU 上,訓練一個基於 Qwen-Image 模型的 LoRA(Low-Rank Adaptation)風格模型。Qwen-Image 是一個 20 億參數的巨型模型,通常需要更高規格的硬體(如 32 GB VRAM 的 RTX 5090),但作者透過創新技術(如量化與 Accuracy Recovery Adapter)實現了在消費級 GPU 上的訓練。影片強調這是對先前影片的延續,先前影片曾在 5090 上使用 6-bit 量化訓練角色 LoRA,而本次聚焦於更常見的 24 GB VRAM 硬體。