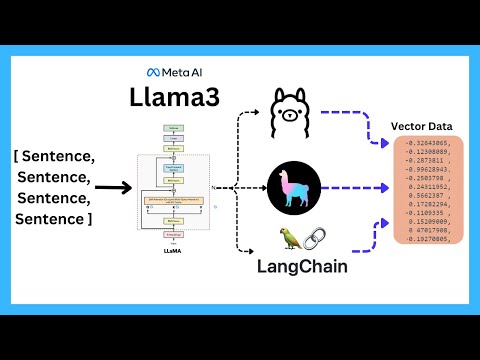
🔥三分钟为GraphRAG实现3D知识图谱!从Parquet到3D可视化,用Python打造3D知识图谱:NetworkX与Plotly的完美结合 #graphrag #rag #知识图谱 #ai

LLM 實際上不會直接處理文字中的單字,而是使用可以表示單字、單字的一部分、單字甚至單字組的標記。在訓練和推理(透過提示與模型互動)期間,稱為標記生成器的預處理元件使用特定的標記化演算法將文字轉換為標記。當Token 學習訓練資料之間的統計關係以及隨後基於這些學習到的關係使用機率創建新文本時,Token 使用的是標記而不是單字。
讓我們來看一個非常簡化的、假設的、非標準的範例,其中我們有一個將單字分解為音節的標記化方案:
人類可能會將這句話視為 6 個字:A cat is a furry animal.
然而,使用我們假設的標記器的Token 將看到 10 個標記: A cat is a Fur ry an i mal 。
實際上,位元組對編碼 (BPE – Byte Pair Encoding ) 或 WordPiece 等標記化演算法要複雜一些,此範例僅用於說明目的。
基於以下幾個原因,區分單字和標記非常重要:
1)當我們談論上下文視窗和最大上下文(模型在單一提示期間可以處理的資料量,即 8K上下文)時,我們討論的是 Token(標記)的數量,而不是字元或單字的數量。
2) 了解Token 使用的是標記而不是單詞,有助於鞏固Token 基於統計模式而不是理解來產生文本的概念。
3)這種方法並非沒有複雜性。標記化難以計算單字數、計算單字中字母出現次數等的幾個原因之一。
那為什麼要使用標記化而不是單字呢?Tokenization 實際上已經使用了幾十年(在 LLM 出現 之前),並且基於一些相同的原因。
1)更好的 “意思”,能夠在訓練期間和稍後的推理過程中在訓練資料的各個部分之間形成更精確的關係。例如,如果您問 “What is a cat?”。LLM 可以開始預測“貓是毛茸茸的”,然後可以選擇“-ry”、“-red”、“-covered”等,這比必須在所有對象之間創建關係更有效個別的話。
2)透過對相似的單字部分進行分組來提高效率,減少模型大小和計算負載。
3)跨語言和翻譯任務或概念化未知單字時的好處。
一些負面因素是標記化確實增加了複雜性,並且可能會導致 Token 的某些問題領域出現問題,例如計算單字數、計算單字中的字母等。
簡而言之,Token 不會像人類那樣使用或理解語言,而是將語言分解成片段,在訓練期間學習這些片段之間的關係,然後以相同的方式分解用戶輸入,以根據機率生成新文字.
手把手教大家如何去訓練自己的大模型知識庫(rag),並且通過llama+langchain+faiss搭建一套基於大模型的問答系統 (Google colab)