更新主要圍繞著使用者介面客製化、錯誤處理機制改進、以及新增多項功能三個面向。 更新包含了自定義首頁和應用程式頁面樣式、更友善的藍屏錯誤顯示及除錯API、預設整合 uv 命令和磁碟空間重複數據刪除功能,以及新增 JSON API (包含json.get、json.set、json.rm)提升資料操作效率。此外,還加入了瀏覽器自動化功能 (整合 Playwright),應用程式設定精靈簡化環境變數設定,Huggingface API 整合方便模型下載,以及新的檔案系統 API (fs.open, fs.cat)和檔案瀏覽器整合。最後,也修復了一些錯誤,例如特定埠衝突問題和Mac系統相容性問題。 整體而言,此更新增強了Pinokio的易用性、穩定性和功能性。
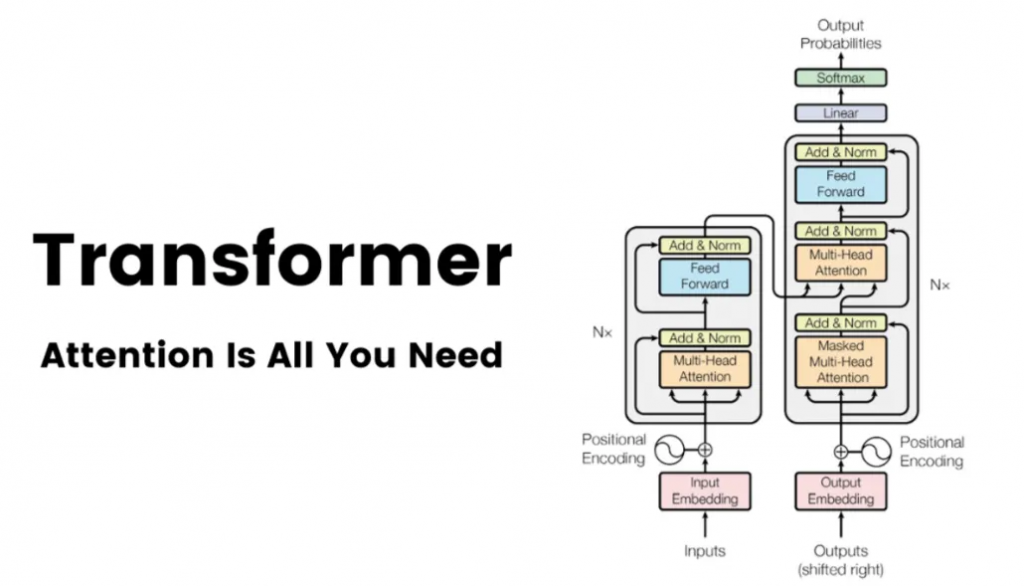
2017 年夏天,一群 Google Brain 研究人員悄悄發表了一篇將永遠改變人工智慧發展軌跡的論文。這份 “注意力就是你所需要的一切” (Attention Is All You Need) 的學術論文。當時人工智慧研究界之外很少有人知道這一點,但這篇論文將為你今天聽說過的幾乎所有主要生成式人工智慧模型奠定基礎,從 OpenAI 的 GPT 到 Meta 的 LLaMA 變體、BERT、 Claude、Bard 等。