DeepSeek 開放源碼週(Open Source Week)是由中國人工智能初創公司 DeepSeek 在 2025 年 2 月 24 日至 2 月 28 日舉辦的一項活動,旨在展示它的建構開放、同埋協作性 AI 生態系統的承諾。在此期間,DeepSeek 每天發布一個開源代碼庫,總共有五個,這些代碼庫已在實際環境中得到驗證並已經開始應用於線上服務。

DeepSeek 開放源碼週(Open Source Week)是由中國人工智能初創公司 DeepSeek 在 2025 年 2 月 24 日至 2 月 28 日舉辦的一項活動,旨在展示它的建構開放、同埋協作性 AI 生態系統的承諾。在此期間,DeepSeek 每天發布一個開源代碼庫,總共有五個,這些代碼庫已在實際環境中得到驗證並已經開始應用於線上服務。
谷歌的 Titans 架構靈感來自人類記憶方式,包括短期、長期和持久記憶。Titans 的長期記憶能夠主動搵出相關資訊及時更新,而持久記憶就可以儲存推理技能,因此能夠擴展前文後理,並且能夠保持高準確性。

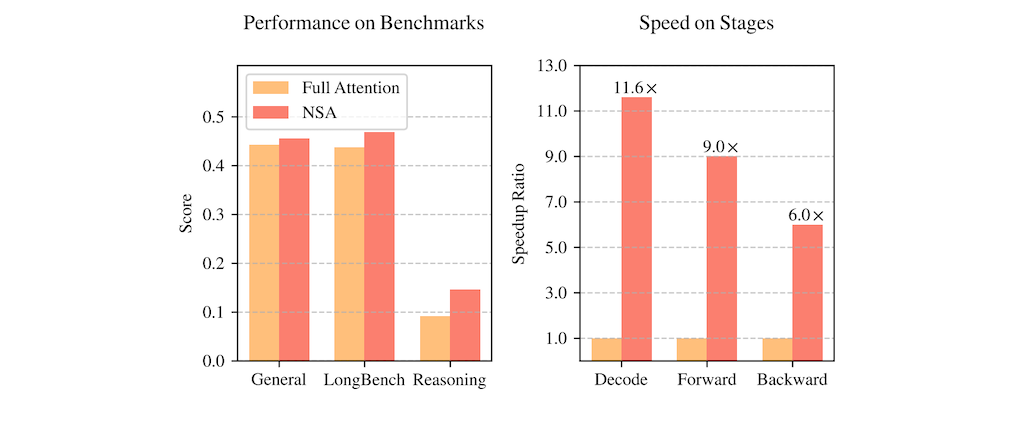
2025 年 2 月 16 日,DeepSeek 提出了一種名為「原生稀疏注意力」(NSA)
Natively trainable Sparse Attention 的新型注意力機制,目的是解決長傳統注意力機制運算量過大的問題。NSA 透過結合分層式 Token 壓縮與硬體加速設計,達成既能有效處理長文本,又不會顯著增加運算負擔的目標。其核心創新點在於演算法與硬體協同優化,保持甚至超越完整注意力模型的性能。實驗證明,NSA 在多項基準測試中表現出色,並且在解碼、前向傳播和反向傳播階段都顯著加速。

這是近期較完整的影片,總結了近期在人工智慧影片技術上的突破,這些技術正快速改變著影片製作的流程。影片亦展望了未來 AI 和 3D 影片的融合創作,能夠在一個統一的場景圖中,以更高的抽象層次協調和導演式的指揮創作,實現更輕量化、更高效的影片製作流程。

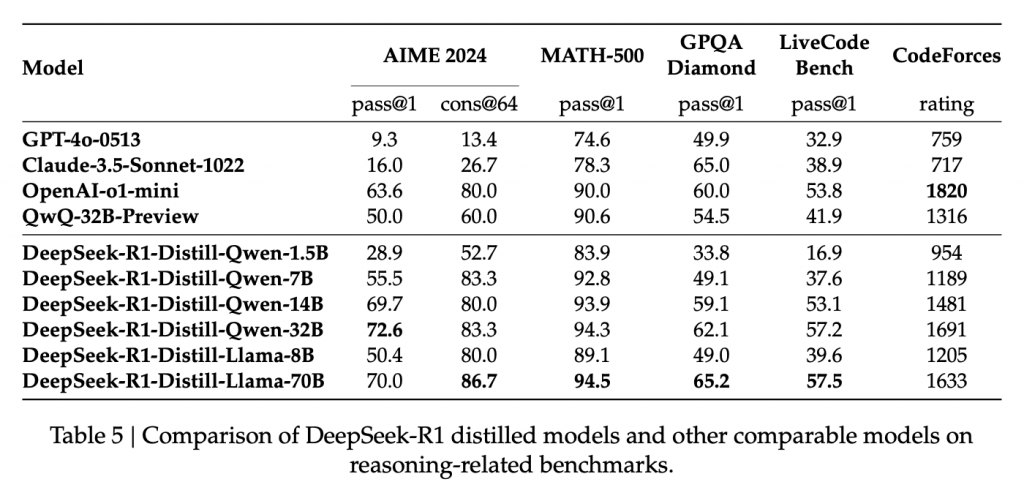
這篇論文介紹了 DeepSeek 團隊開發的兩個大型語言模型:DeepSeek-R1-Zero 和 DeepSeek-R1,它們的核心目標是提升 LLM 的推理能力。DeepSeek-R1-Zero 利用大規模強化學習 (RL) 從頭訓練,展現出令人驚豔的推理能力,儘管存在可讀性和語言混雜等問題。DeepSeek-R1 則在 DeepSeek-R1-Zero的基礎上,加入多階段訓練和冷啟動數據,進一步提升效能,其推理能力已能與 OpenAI 的 o1-1217 模型相媲美。論文也展示了將DeepSeek-R1 的推理能力蒸餾到較小模型的成果,並公開釋出多個不同規模的模型,供研究社群使用。 論文詳細闡述了訓練方法、評估結果以及一些失敗的嘗試,為LLM推理能力的提升提供了寶貴的經驗和見解。
總結模型能力對比
DeepSeek-R1 在函數調用、多回合任務、複雜角色扮演以及 JSON 輸出等方面的能力優於 DeepSeek-V3。
未來研究方向
解決語言混合問題,目標是在未來解決這一限制。
提升提示工程的穩健性,建議用戶直接描述問題並使用零樣本設置指定輸出格式以獲得最佳效果。
探索利用 CoT(Chain-of-Thought)來增強這些領域的任務能力。
推理過程的挑戰
儘管 MCTS 與預訓練價值模型結合使用可以提高推理效率,但通過自我搜索迭代提升模型效能仍然是重大挑戰。
冷啓動強化學習
在冷啓動階段,利用檢查點收集數據並結合監督微調(SFT)來自其他領域的數據,增強模型在寫作、角色扮演和其他通用任務中的能力。
針對 CoT 在語言混合方面的問題,引入了語言一致性獎勵,以提高模型的性能。
作者進行五個關於 DeepSeek R1 以及其他模型(Claude 3.5、OpenAI)的實驗。
實驗一測試模型生成 3D 瀏覽器模擬程式碼的能力,結果 DeepSeek R1 成功完成;
實驗二結合 Claude 的功能與 DeepSeek R1 的推理機制,實現更複雜的資訊處理;
實驗三探討模型在一個數值猜測遊戲中的推理過程,展現了模型的思考步驟;
實驗四修改經典的河渡問題,測試模型是否能跳脫既有訓練資料的限制,DeepSeek R1和Claude成功解決,OpenAI則失敗;
實驗五則以情境題測試模型的連續推理能力,多個模型皆能得出正確結論。
整體而言,影片旨在展示大型語言模型的程式碼生成、工具使用、推理能力以及突破訓練資料限制的潛力,並分享作者對模型能力的觀察與思考。

開源人工智慧模型 DeepSeek R1 在樹莓派上以每秒 200 個 token 的速度運作,這是個突破性進展。重點在於此模型的效能即使在資源受限的樹莓派上也能達到令人驚訝的表現,並超越某些商業模型,例如OpenAI的某些版本。文章同時比較了不同硬體平台(如樹莓派、桌上型電腦、高效能GPU)運行此模型的效能差異,並探討了其在遊戲NPC應用上的潛力,強調其離線運作、低延遲以及可定制性等優點。

瑞士 FinalSpark 實驗室利用腦部類器官 (brain organoids) 開發生物電腦的最新進展。這些微小的球狀物,由約一萬個從幹細胞培養而成的腦神經元組成,被放置在培養器中並連接到電極,以便進行通訊和訓練。此研究屬於生物運算 (bio-computing) 或稱濕件 (wetware) 的領域,目標是創造比現今電腦更節能且高效的運算系統,並可能徹底改變人工智慧系統。

谷歌最近的人工智慧計畫是模擬整個物理世界的系統,谷歌認為這是通往通用人工智慧的關鍵路徑,以及它如何與谷歌更廣泛的人工智慧策略相連,這當然包括 Gemini。
這是 Google DeepMind 一項突破性的 AI 計畫:建構模擬整個物理世界的系統,以朝向通用人工智能 (AGI) 邁進。該系統整合了多模態數據 (例如影片、音訊和機器人數據),用以模擬真實世界的物理規律,並將應用於機器人、遊戲和科學研究等領域。 這項計畫展現 Google 擴展 AI 模型以達到前所未有的智能和真實感的雄心壯志,並預期將對各產業帶來革命性的影響,加速 AGI 的實現。

NVidia Lab(NVlabs) Sana 是一個高效的文字轉圖像模型,其核心設計包含高效的編碼器-解碼器架構 (DC-AE)、線性擴散變換器 (Linear DiT)、僅解碼器的文字編碼器,以及 高效的訓練和採樣方法 (Flow-DPM-Solver),讓它能快速生成高解析度 (最高 4096×4096) 的高品質圖片。相較於其他大型擴散模型,Sana 模型體積小,速度快,甚至可在 16GB 的筆電 GPU 上執行,生成 1024×1024 解析度的圖片只需不到一秒鐘。文件中包含了模型的架構說明、效能數據、使用方法(包含使用 Hugging Face Diffusers 的方式)、訓練方法以及未來的發展方向等資訊。
