比較 6 個亞洲人模型

比較 6 個亞洲人模型
Awni Hannun 宣怖 Apple 正式開放 ML Framework 並於 GitHub 設立模型庫及應用介面範例。各種使用MLX 框架的獨立範例。
MNIST範例是學習如何使用 MLX 的良好起點。
一些更有用的例子包括:
從今天開始,Google Bard 將使用 Gemini Pro 的微調版本來進行更高級的推理、計劃、理解等。 這是 Bard 自推出以來最大的升級。 它將在 170 多個國家和地區提供英語版本,我們計劃在不久的將來擴展到不同的模式並支援新的語言和地點。
原生多模態(Natively Multimodel):Google Gemini 的突破
以往創建多模態大模型的方法,通常是先分別訓練文本、圖像、音頻等單一模態的模型,然後將它們拼接在一起。這樣的模型雖然在某些特定任務上表現不錯,不過面對更具概念性,或者複雜推理的任務,往往表現不太理想。
Gemini 提出了原生多模態的概念,即從一開始就對不同的模態進行整合訓練,然後用額外的多模態數據進行微調。這樣訓練出來的模型可以更好地理解不同模態之間的關係,從而提高在複雜任務上的表現。
Google 還將 Gemini 引入 Pixel。 Pixel 8 Pro 是第一款運行 Gemini Nano 的智慧型手機,它支援記錄器應用程式中的 Summarize 等新功能,並從 WhatsApp 開始推出 Gboard 中的智慧回覆功能,明年還將推出更多訊息應用程式。
在接下來的幾個月中,Gemini 將出現在我們更多的產品和服務中,例如搜尋、廣告、Chrome 和 Duet AI。
Google 已經開始在搜尋器中試驗 Gemini,它使用戶的搜尋生成體驗 (SGE) 更快,延遲減少了 40%,同時品質也提高了。

從爵士樂到重金屬,從電子音樂到歌劇,音樂是一種深受人們喜愛的創意表達形式。到目前為止,由於歌詞、旋律、節奏和人聲複雜且層次豐富,創作引人入勝的音樂對於人工智慧 (AI) 系統來說尤其具有挑戰性。
今天 與 YouTube 合作,宣布推出 Google DeepMind 的 Lyria,這是我們迄今為止最先進的人工智慧音樂生成模型,以及兩項旨在為創造力開闢新遊樂場的人工智慧實驗:
為了開發這些項目,我們匯集了來自 Google 各地的技術專家以及眾多世界知名藝術家和歌曲作者,共同探索生成音樂技術如何負責任地塑造音樂創作的未來。我們很高興能夠建立新技術,以增強專業音樂家和藝術家社群的工作,並為音樂的未來做出積極貢獻。
Google DeepMind,前稱DeepMind科技(DeepMind Technologies Limited),是一家英國的人工智慧公司。公司建立於2010年,在2014年被Google收購。
先進的 AI 腳本生成器在幾分鐘內生成引人入勝的腳本,並將它們無縫地呈現為動態說話頭像影片。
Vibro 有趣的地方是當使用 A.I. 生成劇本,它讓你將原來輸入的劇本進行個性化。例如我輸入:
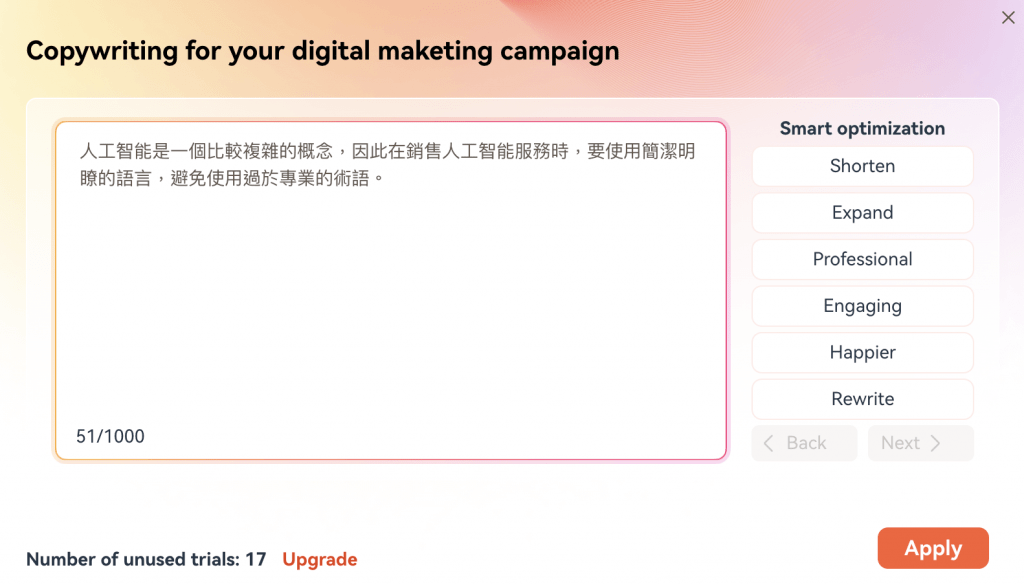
按一下 “Expand” 之後,它回自動修改你的內容:
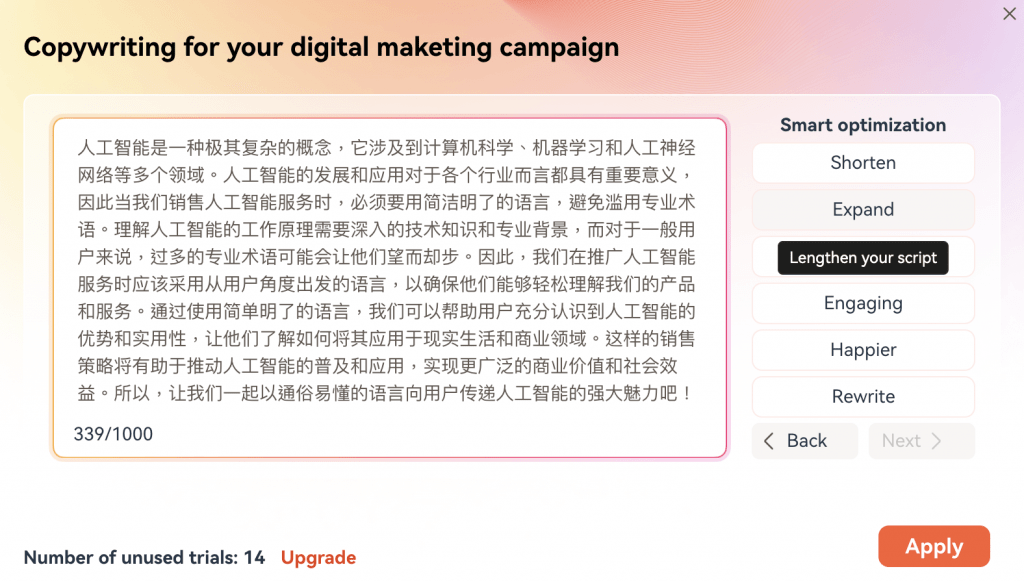
Vibro 提供免費試用,限制輸出為兩分鍾的影片。不過,細心觀察以下影片,你會發現 LipSync 效果似乎仍有待改善。
至於廣東話發音,免費版提供 2 女 1 男聲:



OpenAI 也制定了保護措施,阻止使用者產生色情或暴力圖形藝術或公眾人物圖像。OpenAI 的政策研究員 Sandhini Agarwal 表示,對於色情內容的非常明確的請求,必須經過分類器並且會被拒絕。
Dall-E 3 還允許用戶透過 ChatGPT 來完善創作,就好像他們要求真正的藝術家進行更改一樣。「你真的不必擔心很長的提示,」首席研究員兼 Dall-E 團隊負責人 Aditya Ramesh 說。“相反,您可以與 ChatGPT 進行交互,就像與同事交談一樣。”
Dall-E 團隊的首席研究員 Gabriel Goh 向《Wired》雜誌展示了這項技巧,他要求 Dall-E 3 為一家想像中的麵館製作幾張宣傳海報。在收到幾個選項後,Goh 透過 ChatGPT 要求 Dall-E 3 選擇其中一個並將其變成懸掛在餐廳外的標誌的插圖。
Dall-E 3 現已透過付費版本 ChatGPT Plus 提供。





