PaperBanana 是一個開源的自動化學術圖表生成框架,由 Google Research 開發。這個工具專為 AI 研究人員設計,能夠自動生成符合出版標準的方法論圖表、代理架構和統計圖 。
PaperBanana 還擁有強大的潤色功能。您可以輸入手繪草圖或示意圖,系統會將它們精修成專業的向量圖。Google 聲稱兩星期後會提供開源實作版本,亦有第三方的版本可在 GitHub 下載使用。
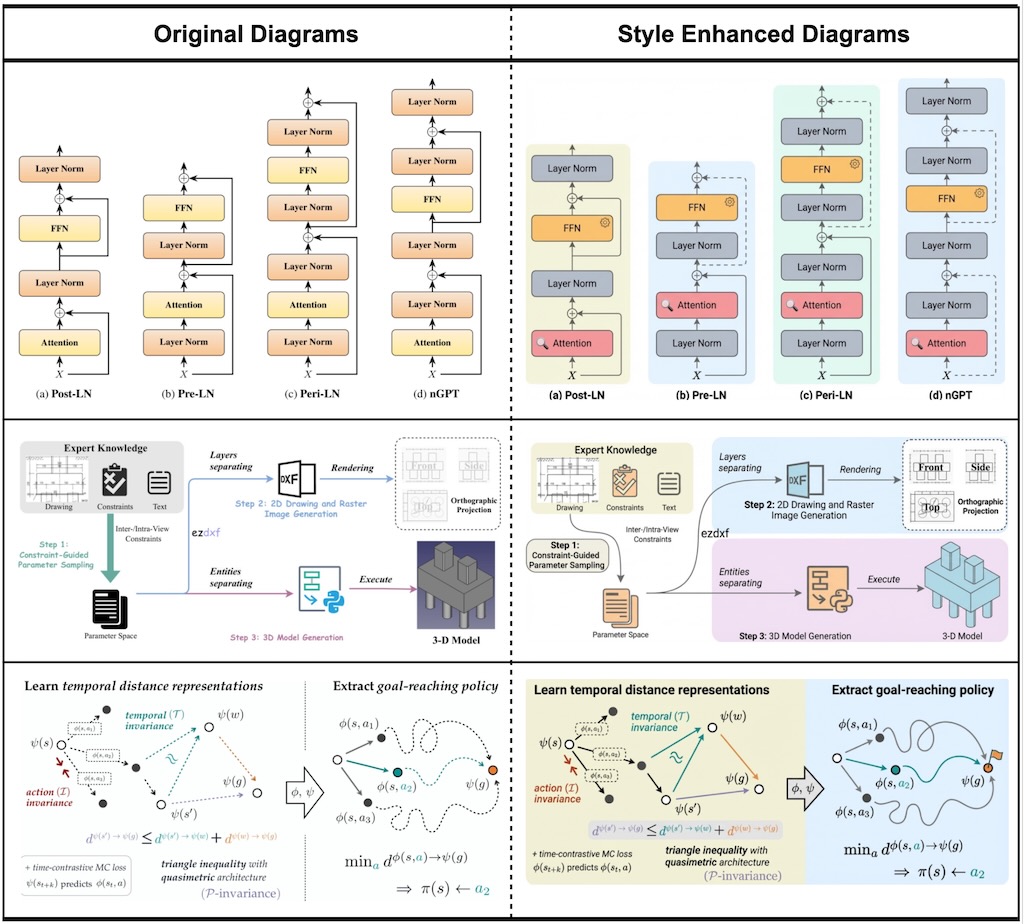
PaperBanana 是一個開源的自動化學術圖表生成框架,由 Google Research 開發。這個工具專為 AI 研究人員設計,能夠自動生成符合出版標準的方法論圖表、代理架構和統計圖 。
PaperBanana 還擁有強大的潤色功能。您可以輸入手繪草圖或示意圖,系統會將它們精修成專業的向量圖。Google 聲稱兩星期後會提供開源實作版本,亦有第三方的版本可在 GitHub 下載使用。

Apple 和 Google 達成一項為期多年的合作。未來一代的 Apple Foundation Models(蘋果自家基礎模型)將建立在 Google 的 Gemini 模型與雲端技術之上。
這些模型將用來支援未來的 Apple Intelligence 功能,包括今年會上線的更個人化版 Siri。
Conductor 是 Google 推出的一個 Gemini CLI 擴充套件,目前處於預覽階段,它透過「脈絡導向開發」(context-driven development)改變開發流程,讓開發者在編寫程式碼前先建立正式規格與計劃,並將其儲存為持久化的 Markdown 檔案。


科學研究不斷表明,真正的學習需要積極參與。這正是 Gemini 幫助您學習的根本所在。除了簡單的文字和靜態圖像,我們現在還在Gemini 應用中推出互動式圖像——這項新功能旨在幫助您以視覺化的方式探索複雜的學術概念。
想像你在研究消化系統或細胞結構。現在,你不再只能看到標籤,而是可以直接點擊圖表中的特定部分,解鎖一個互動式面板。此面板提供即時定義、詳細解釋以及可供深入研究的內容。
透過與圖像互動,Gemini 將學習方式從被動觀看轉變為主動探索。現在,透過某些影像,您可以獲得更多相關主題資訊並提出後續問題。這標誌著學習方式朝著更直覺、更動態、更易於理解的方向邁出了重要一步。
Paper2Video 能從輸入的論文(LaTeX源碼)、一張圖片和一段音頻,生成完整的學術報告視頻。集成了幻燈片生成、字幕生成、游標定位、語音合成、講者視頻渲染等多模態子模塊,實現一條龍的演示視頻製作流程。支持並行處理以提升視頻生成效率,推薦GPU為NVIDIA A6000(48G顯存)及以上。
需要設定 GPT-4.1 或 Gemini2.5-Pro 等大型語言模型 API Key,支持本地 Qwen 模型。
影片中,作者使用了 Google 的 embedding 模型和 ChromaDB 向量資料庫來實現這個架構。
影片強調動手實作的重要性,鼓勵觀眾親自寫一遍程式碼以加深理解。

Google Firebase Studio 的目標是盡量簡化開發流程,就算你是剛剛開始學寫 App 也不用擔心。只要你有基本了解,Firebase Studio 可以透過 AI 助手 Gemini 幫你寫 Code、Debug 同埋改善效能。完成了之後,無論是全方位的應用程式,抑或 API、後台、前端同埋手機 App,佢都可以幫你自動整合發佈。測試期間,你可以擁有 3 個的免費工作空間。

Embedding 文字嵌入,意思是將文字轉換為有意義的向量數值。其主要目的是為了讓 A.I. 開發者能夠利用這些向量,實現更精準的語義搜尋,即使查詢與文本內容的詞彙不完全相同也能找到相關資訊。
Google 宣布推出一個新的實驗性 Gemini 文字嵌入模型,稱為 gemini-embedding-exp-03-07。這個模型繼承了語言和細微語境的理解,適合廣泛的應用。這個新模型超越了 Google 之前的最先進模型,並在多語言文本嵌入基準測試(MTEB)中名列前茅,同時還提供了更長的輸入長度等新功能。目前已經可以透過 Gemini API 開始使用。

透過 Gemini 2.0 API 和 Next.js 框架,作者分享了如何建構一個實時多模態應用程式。佢能夠接收影像和語音輸入,並透過 WebSocket 傳送至 Gemini API。Gemini API 會生成音頻輸出和文字轉錄,然後整合到有互動功能的聊天介面。教學包括深入探討應用程式的各個組件部分,例如媒體擷取、音訊處理、WebSocket 連線、轉錄服務以及用戶介面的更新。作者亦提供了開源的程式範例,並且逐步加以說明,方便大家由 GitHub 複製,並執行這應用程式。
