FramePack 是一種新的視頻擴散設計,用壓縮上下文令工作量不會隨著影片的長度而增加,只需一張圖片,就可以令你的 6GB vRAM 的電腦透過 13B 模型生成每秒 30 格影片的 60 秒影片。而用 RTX 4090 的話,最快速度為每格 1.5 秒。
作者 Lvmin Zhang
FramePack Run In Gradio & ComfyUI - Generate Long Length image2Video AI Video - Installation Guide

FramePack 是一種新的視頻擴散設計,用壓縮上下文令工作量不會隨著影片的長度而增加,只需一張圖片,就可以令你的 6GB vRAM 的電腦透過 13B 模型生成每秒 30 格影片的 60 秒影片。而用 RTX 4090 的話,最快速度為每格 1.5 秒。
作者 Lvmin Zhang
ComfyUI-Manager 在 3 月 28 日遷移至 ComfyUI 開發團隊所在的 GitHub Repository。因此我相信 ComfyUI 能夠持續提升使用者體驗。提供一鍵安裝、節點管理。如果您經常探索最新的 AI 繪圖技術,抑或需要特定的圖像處理節點,ComfyUI Manager 都能夠令相關操作流程更為簡易及高效。
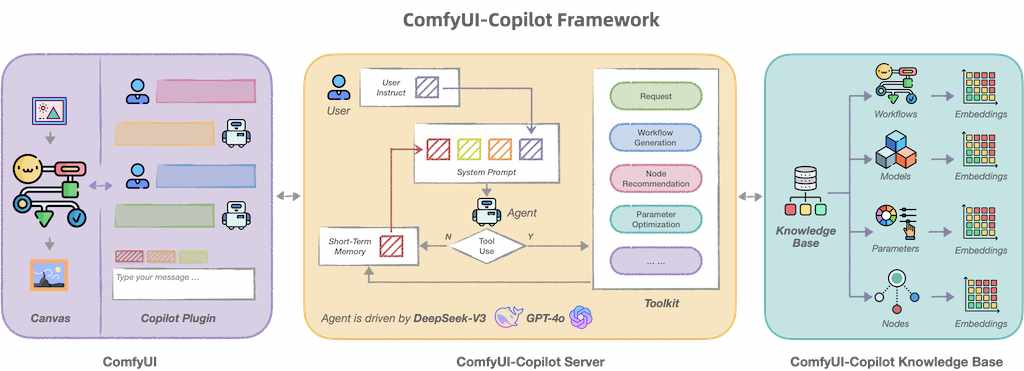
ComfyUI-Copilot 是基於 ComfyUI 框架構建的智能助手,通過自然語言交互簡化並增強 AI 算法調試和部署過程。無論是生成文本、圖像還是音頻,ComfyUI-Copilot 都提供直觀的節點推薦、工作流構建輔助和模型查詢服務,以簡化您的開發過程。
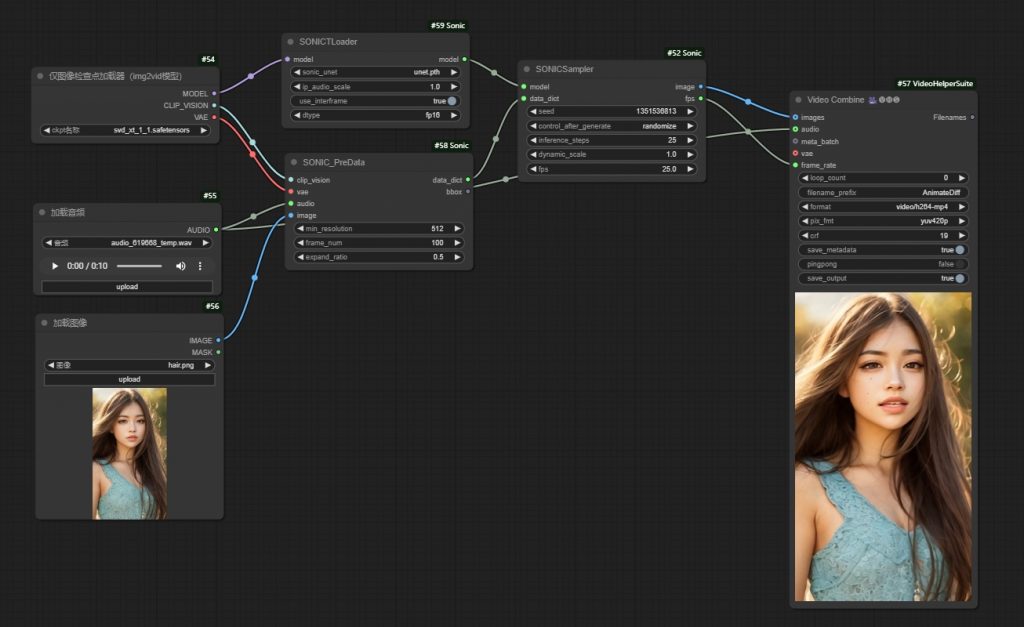
Sonic 不單將音訊對應到嘴型,而是更全面理解音訊的內容和情感,進而產生更自然、更加生動的人像動畫。可以配合 ComfyUI_Sonic 使用。項目亦包括 Realtalk 即時同逼真的音訊驅動人臉生成技術。新增 frame number 選項,可以控制輸出影片的長度。亦可基於音頻長度。
ACE++ 基於指令的擴散框架,只要輸入一張圖像即可生成與角色一致的新圖像,專門用來處理各種圖像生成和編輯任務。靈感來自 FLUX.1-Fill-dev 的輸入格式,以雙階段訓練方法來減少對圖像擴散模型進行微調所需的工作量。這框架提供了全面的模型集,涵蓋了完整微調和輕量級微調,在生成圖像品質和遵循提示能力方面展現了卓越的性能,可以廣泛應用於人像一致性、靈活指令描述和局部編輯等不同情境。

Comfy-WaveSpeed 目標是為 ComfyUI 圖像生成工具提供全面、靈活且快速的推論優化方案。核心功能包含動態快取機制(First Block Cache),能透過重用先前計算結果來加速運算,以及增強版的 torch.compile,用以提升模型編譯效率。 專案目前仍在開發中(WIP),支援多種模型,例如 FLUX 和 LTXV,並提供使用教學和示範工作流程。 整體而言,Comfy-WaveSpeed 旨在提升 ComfyUI 的圖像生成速度,同時盡可能維持圖像品質。
以下影片是提升 ComfyUI 效能的教學,重點在於加速 AI 影像與影片生成的流程。教學內容涵蓋 Comfy WaveSpeed 的安裝設定、PyTorch 和 CUDA 的記憶體優化技巧、GGUF量化和模型快取的步驟指南,以及使用 Hunyuan Videos 和 Flux 展示效能提升的實例。 其目標在於幫助使用者解決 AI 生成任務中常見的漫長生成時間和記憶體瓶頸問題,並透過 Purge VRAM 等方法確保系統穩定運行。

一個能獨立執行的 ComfyUI 版本,內含 ComfyUI、ComfyUI_frontend、ComfyUI-Manager 和 uv 等元件,並自動安裝 Python 庫。同時詳細說明了不同作業系統(Windows、macOS、Linux)下的安裝路徑、檔案結構,以及開發者設定和建置流程,包含 Python版本、Node.js 和 Yarn 的安裝與使用,以及如何使用 comfy-cli 工具安裝 ComfyUI 資源和相依套件。此外,它也提及了錯誤回報機制,強調只收集未處理例外和原生程式崩潰的堆疊追蹤,不會傳送個人資料、工作流程或日誌,並使用 Sentry 進行錯誤報告。核心目的是提供 ComfyUI 桌面應用的安裝、設定、開發和發佈指南,著重於跨平台相容性和開發環境的建置。
Fast Video Framework 大幅提升本地 AI 影片生成速度,同時維持高畫質。 透過 LCM 取樣和 LoRA 整合,讓 Hunyuan Video 和 Mochi One Preview 等模型在一般家用電腦上也能快速運作,並減少資源消耗。 片中以 ComfyUI 為例,逐步示範如何設定與使用,包含壓縮儲存、整合 LoRA 模型等步驟,讓使用者能輕鬆高效生成各種風格的影片。

它能利用兩個新的 Flux 模型(Flux Fill 和 Flux Redux)將衣服穿戴在人物模型上。能精準且智慧地將各種服飾,例如襯衫、褲子、鞋子、眼鏡和帽子等,甚至多件服飾同時,完美地套用到圖片中的人物身上,實現以往難以達成的穿衣效果。

影片作者 Mickmumpitz 展示如何利用 ComfyUI,以及幾個開源 AI 影像模型 (例如 Co video x, LTX Video, Machi 1, Hyan),將自家拍攝的影片轉化成具有電影感的史詩級畫面。影片重點在於如何使用這個 AI 工作流程,包含設定、模型選擇 (不同模型各有速度與畫質的優劣)以及控制網路 (Control Net) 的應用,以達到精準控制影像生成的目標,例如保留演員表情和動作,或轉換角色外貌。影片也提供免費及付費兩種工作流程,付費版本提供更進階的功能,例如臉部替換和更精細的畫面調整。最後,作者展示了一部以這個方法製作的短片,說明其應用實例。
![Shoot EPIC MOVIES with this FREE AI Tool! [ComfyUI Tutorial + Free Workflow]](https://infernews.com/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FgHI6PjTkBF4%2F0.jpg)