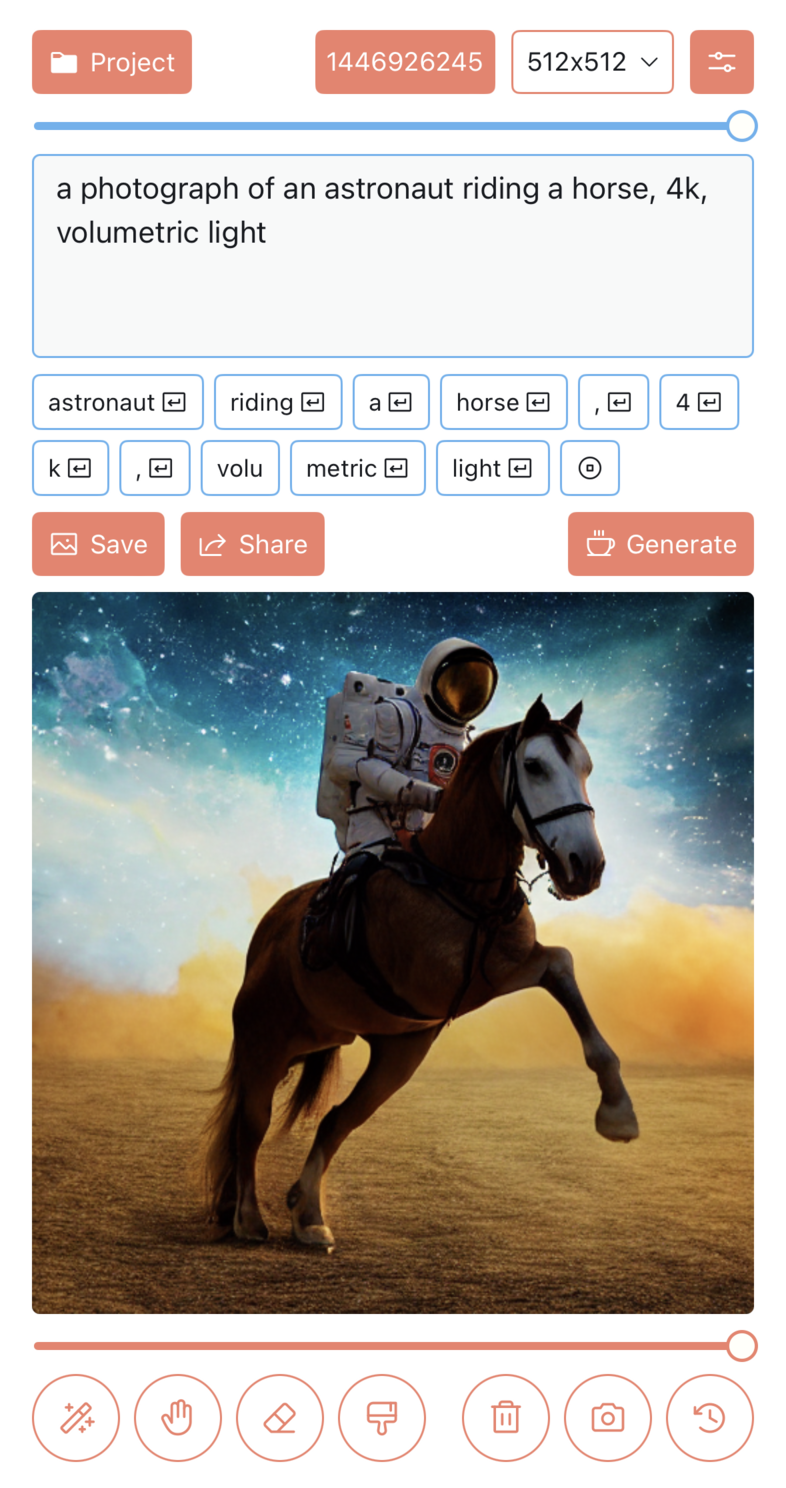
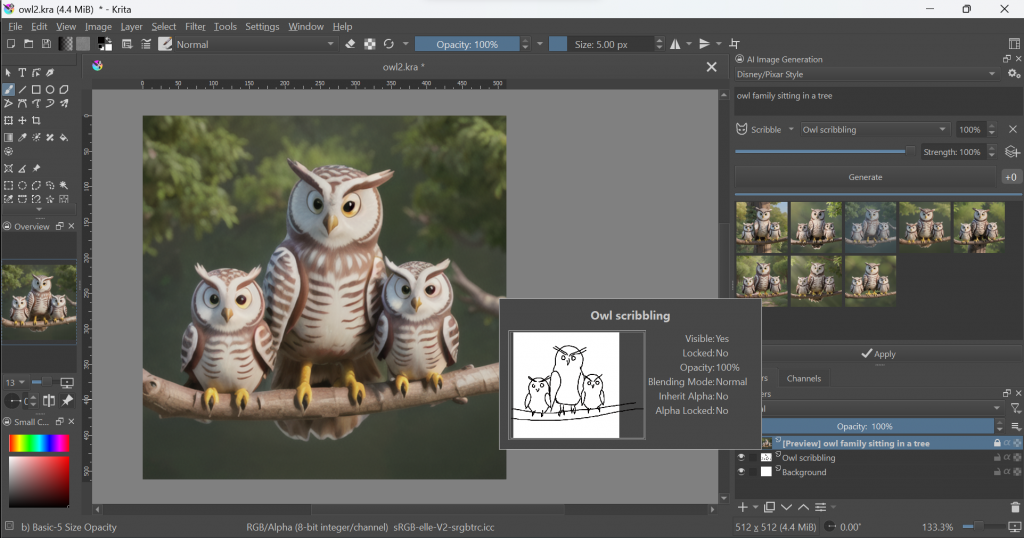
這是個高質量視頻生成框架,使用級聯潛在擴散模型(Cascaded Latent Diffusion Models)進行文本到視頻(Text-to-Video)生成,是Vchitect視頻生成系統的主要組成部分。項目提供了使用PyTorch實現的LaVie的官方代碼。
您可以從GitHub頁面下載。通過文本描述,生成與文本相對應的視頻。項目還提供了預訓練模型和示例代碼,助您進行推理和生成自己的視頻。
LaVie是一個基於機器學習的視頻生成框架,它使用了一種稱為級聯潛在擴散模型(Cascaded Latent Diffusion Models)的技術。這種模型可以通過將文本描述轉化為視頻序列來實現文本到視頻的生成。
LaVie項目的GitHub頁面還提供了示例代碼和相關配置文件,可以幫助您更好地理解和使用該框架。您可以根據示例代碼進行自己的實驗和應用。
請注意,LaVie的使用可能需要具備一定的機器學習和深度學習知識,以及相應的計算資源。如果您對LaVie感興趣,建議您仔細閱讀項目的文檔和代碼,並根據需要進行相應的學習和實踐。