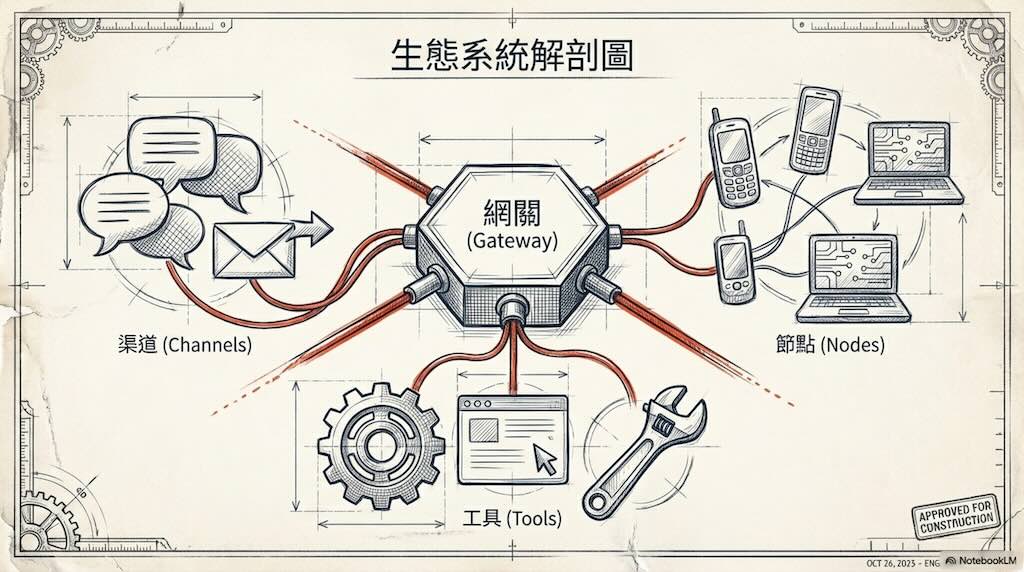
OpenClaw 三個存放 Skill 的地方——搞錯一個你就完了 | 龍蝦客製化、安全避坑一次搞懂 !


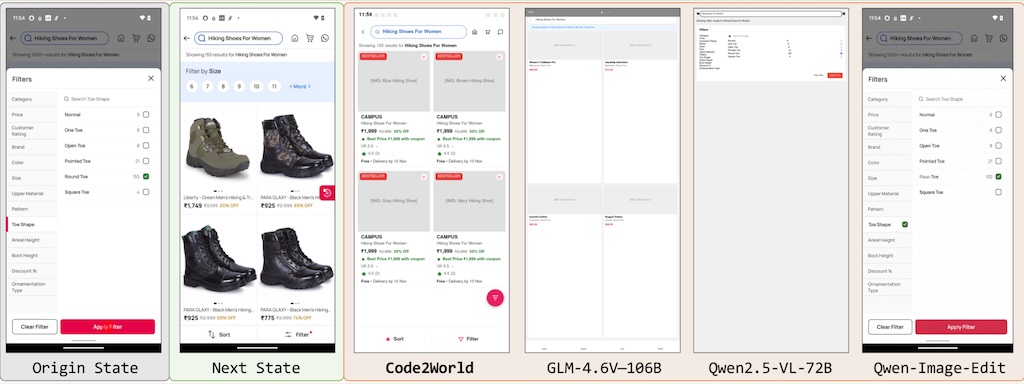
Code2World 本身不是一個「GUI 設計工具」,但它可以用在「優化 GUI 設計」的流程裡,特別是幫你 驗證設計是否好操作、是否容易出錯、是否符合使用者行為預期。Code2World 以靈活的方式顯著提升了下游導航的成功率,在 AndroidWorld 導航方面,其性能比 Gemini-2.5-Flash 提升了 9.5%。
它透過產生可渲染的程式碼來模擬下一個視覺狀態。實驗表明,Code2World-8B 在下一界面 UI 預測方面表現卓越,足以媲美 GPT-5 和 Gemini-3-Pro-Image 等競爭對手。(Huggingface 模型及數據集出現 404)(圖為預測介面的結果)
PaperBanana 是一個開源的自動化學術圖表生成框架,由 Google Research 開發。這個工具專為 AI 研究人員設計,能夠自動生成符合出版標準的方法論圖表、代理架構和統計圖 。
PaperBanana 還擁有強大的潤色功能。您可以輸入手繪草圖或示意圖,系統會將它們精修成專業的向量圖。Google 聲稱兩星期後會提供開源實作版本,亦有第三方的版本可在 GitHub 下載使用。
本週,網路上掀起了一股搶購 Mac mini 的熱潮,人們紛紛購買 Mac mini 來運行 Moltbot(原名Clawdbot)。 Moltbot 是一款開源的、可自行託管的AI代理,旨在充當個人助理。
Clawd 誕生於2025年11月-這是「Claude」加上「爪子」的巧妙雙關。一切都完美無缺,直到Anthropic的法務團隊禮貌地要求我們重新考慮。好吧,這很合理。
Moltbot 這個名字是接下來誕生的,它是在凌晨5點與社區成員在 Discord 上進行一場混亂的頭腦風暴後選定的。蛻皮象徵成長-龍蝦脫殼蛻皮,最終長成更大的生物。這個名字寓意深刻,但 念起來卻不太順口。
OpenClaw 就是我們的最終歸宿。這次,我們做了充分的準備:商標檢索結果清晰無誤,網域名稱已購買,遷移程式碼也已編寫完成。
短短48小時內,OpenClaw 在 GitHub 上就獲得了 12.3 萬顆星。彼得·斯坦伯格(Peter Steinberger)的周末計畫一度成為史上成長最快的開源人工智慧工具——直到安全研究人員檢查了其程式碼並發出警報。 OpenClaw 是一款開源的個人人工智慧助手,可在本地運行並連接到 WhatsApp、Slack、Discord和 iMessage 等應用程式。在2026年1月29日至31日期間,OpenClaw從默默無聞一躍成為擁有超過10萬顆星的開源人工智慧助理。開發者們欣喜若狂,終於可以擁有自己的人工智慧助手,而無需再從雲端服務供應商租用。然而,思科和 IBM 的安全專家卻稱之為 “一場噩夢”,並警告稱其存在API金鑰洩漏、提示注入攻擊和企業資料外洩的風險。
Clawdbot 已於 2026 年 1 月 27 日更名為 Moltbot,因為 Anthropic 因商標相似(Claude)而要求變更。原 Clawdbot 是個人 AI 助理工具,支援多平台運行,現轉為 Moltbot,GitHub 移至 moltbot/moltbot,舊 clawdbot 組織重定向至新名稱。 軟體功能、程式碼與使用方式完全相同,僅品牌與帳號變更(吉祥物從 Clawd 改為 Molty)。
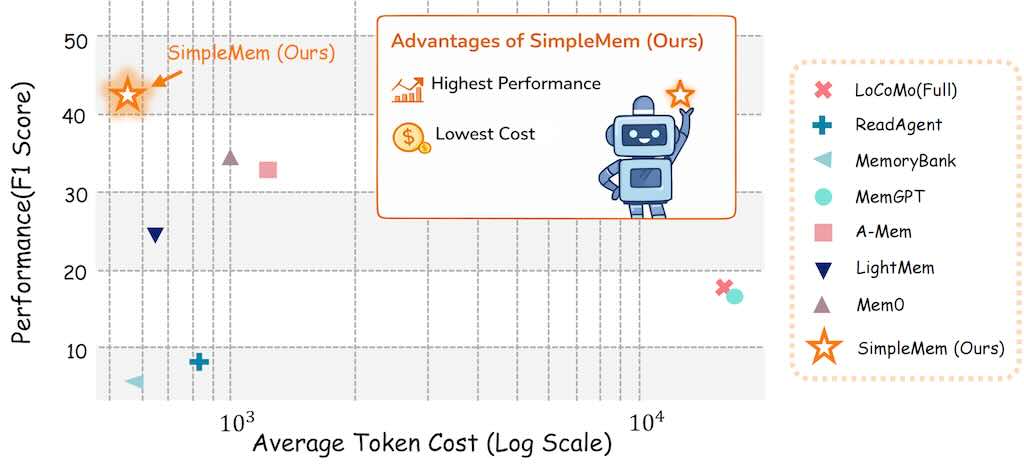
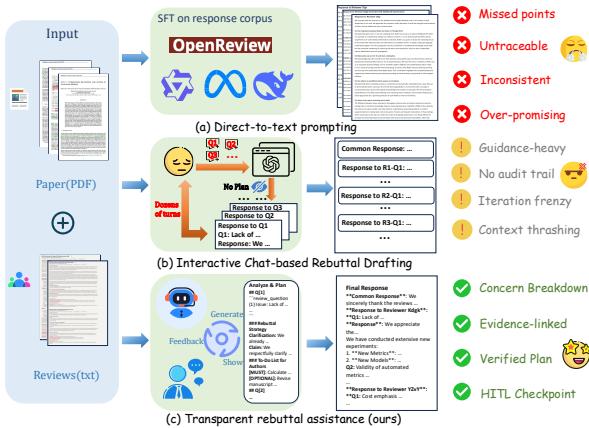
REBUTTALBENCH 是第一個將反駁生成重新定義為以證據為中心的規劃任務的多智能體框架。此方法解決了目前直接處理文字方法的局限性,這些方法常常導致臆想、忽略批評意見以及缺乏可驗證的依據。我們的系統將複雜的回饋分解為原子級關注點,透過將壓縮摘要與高保真文本合成來動態建構混合上下文,並整合一個自主的外部搜尋模組來解決需要外部文獻的問題。至關重要的是,REBUTTALAGENT 在撰寫反駁方案之前會產生一個可檢查的回應計劃,確保每個論點都明確地錨定在內部或外部證據之上。我們在提出的 REBUTTALBENCH 上進行的驗證過程表明,REBUTTALAGENT 在覆蓋率、忠實度和策略一致性方面均優於強大的基線系統,為同行評審過程提供了一個透明且可控的輔助工具。下圖總結了我們的工作,並比較了我們的方法與以往的方法。
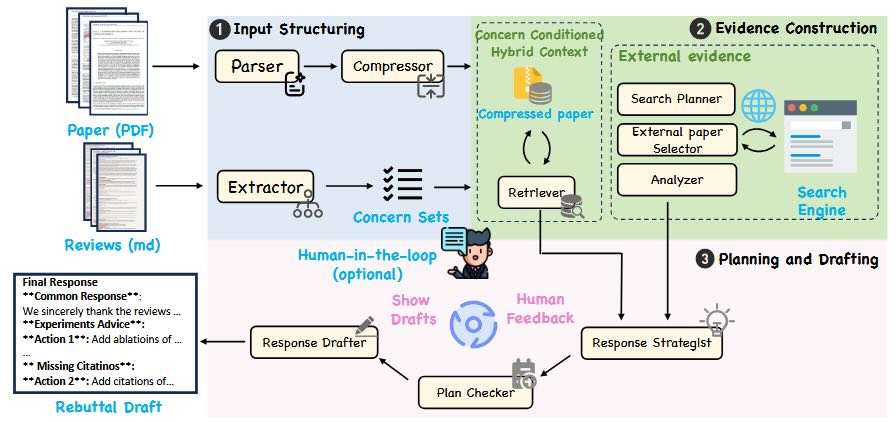
REBUTTALBENCH 是一個多智能體框架,旨在將反駁過程轉化為結構化且可檢查的工作流程。系統在撰寫最終文本之前會產生與證據相關的中間產物,以確保輸出結果的可靠性和可控性。如下圖所示,該架構將複雜的推理過程分解為多個專業智能體,並配備輕量級檢查器。這種設計突顯了關鍵決策點,使作者能夠保留對策略立場和最終措辭的責任。此流程首先將稿件提煉成結構化的摘要,並提取審查者關注的原子性問題,以確保長期推理的穩定性。在這些關注點的指導下,系統透過從稿件中檢索高保真度的摘錄,並利用網路搜尋添加可驗證的外部文獻,建構證據包。工作流程最後產生一個明確的回應計劃,概述論點和證據鏈接,作者可以透過人機協作機制對其進行完善,之後系統將產生正式的反駁信。
REBUTTALBENCH 使用 LLM 作為評判員的評分標準,從相關性(R 分數)、論證品質(A 分數)和溝通品質(C 分數)三個方面,以 0-5 分制對回覆進行評估。下方的詞雲和高頻詞直方圖突出了評審員反覆關注的幾個方面,例如清晰度、新穎性和可重複性,這些也正是評分標準所明確針對的。
agent-browser 專注於為 AI Agent 提供快速、可靠的瀏覽功能。整個專案使用 Rust 撰寫核心腳本,提供高效的執行速度,同時保留 Node.js 作為後備方案,讓開發者可以在不同環境下自由切換。