Spatia,一個感知空間記憶的視頻生成框架,它將三維場景點雲顯式地保存為持久的空間記憶。 Spatia 基於此空間記憶迭代生成影片片段,並透過視覺 SLAM 不斷更新它。這種動態-靜態解耦設計增強了整個生成過程中的空間一致性,同時保持了模型生成逼真動態實體的能力。此外,Spatia 支援顯式相機控制和三維感知互動式編輯等應用,為可擴展的、記憶驅動的視訊生成提供了一個基於幾何基礎的框架。
RePlan 圖像編輯框架
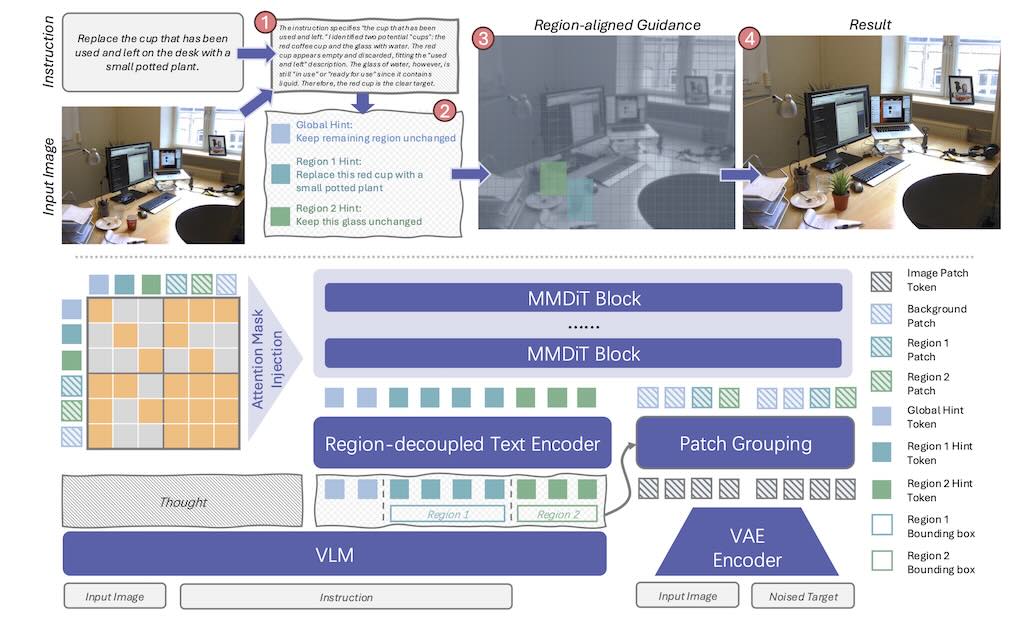
RePlan 是一個基於指令的圖像編輯框架,專門解決指令-視覺複雜度(IV-Complexity)挑戰,透過視覺語言規劃器與擴散編輯器結合實現精準區域編輯。

框架採用「規劃-執行」策略:VLM 規劃器透過逐步推理分解複雜指令,生成邊界框與區域提示;編輯器使用無訓練注意力區域注入機制,支援單次多區域並行編輯,避免迭代 inpainting。
AnyTalker 多人對話唇形同步影片
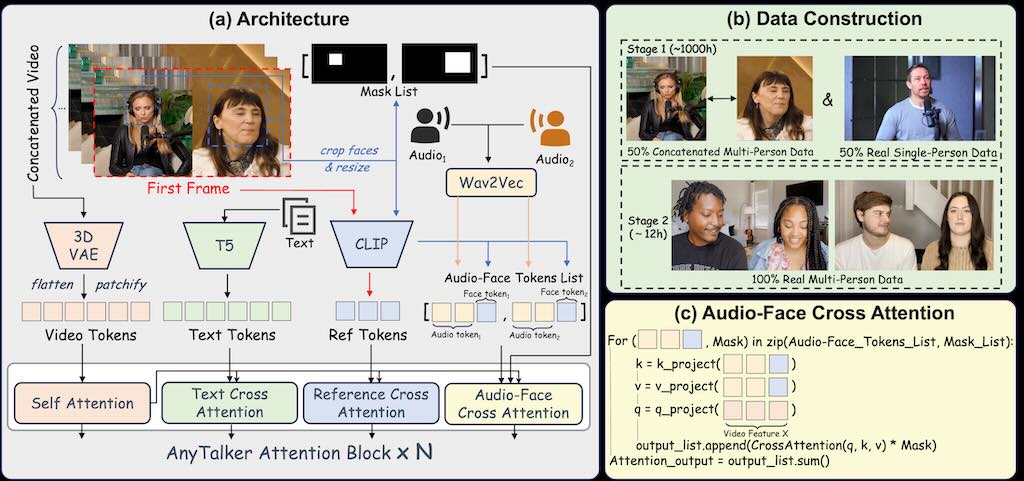
AnyTalker,一個基於音訊的多人對話的開源視訊生成框架。它採用靈活的多流結構,既能擴展身份規模,又能確保身份之間的無縫互動。
UniVerse-1 同步生成有聲影片
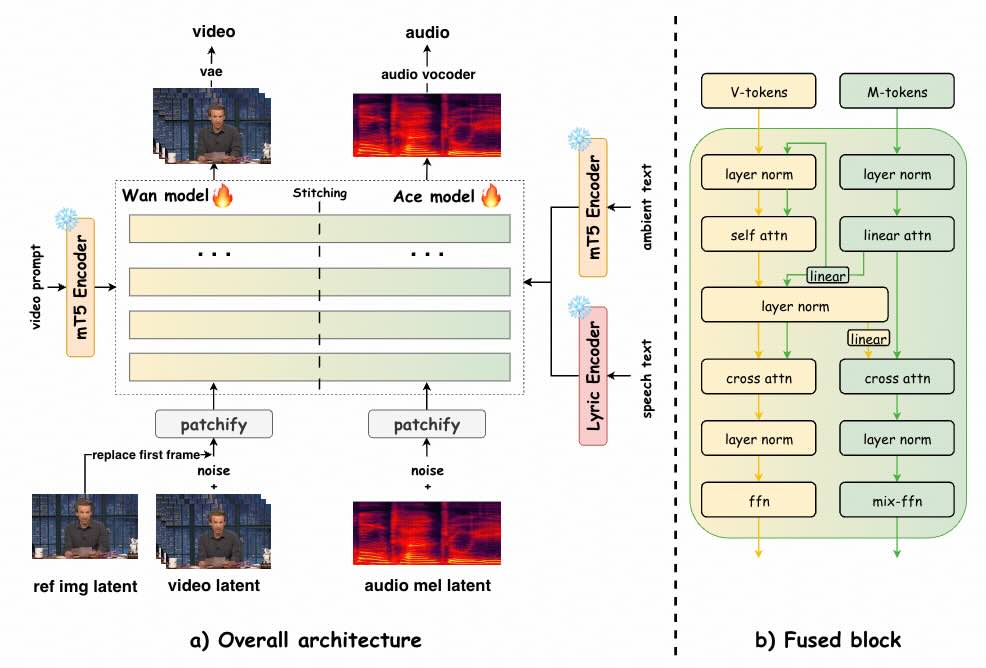
UniVerse-1 是個類似 Veo-3 的模型,可根據參考圖像和文字提示同時產生同步音訊和視訊。
- 統一音視頻合成:具有同時生成音訊和視訊的強大功能。它能夠解析輸入提示,產生完美同步的視聽輸出。
- 語音音訊產生:此模型可直接根據文字提示產生流暢的語音,展現了其內建的文字轉語音 (TTS) 功能。至關重要的是,它能夠根據生成的特定字元調整語音音色。
- 樂器演奏聲音生成:此模型在創造樂器聲音方面也非常熟練。此外,它還提供了「邊彈邊唱」的功能,可以同時產生人聲和樂器音軌。
- 環境聲音生成:此模型可以產生環境聲音,產生與視訊視覺環境相符的背景音訊。
- 第一個開源的基於 Dit 的音訊視訊聯合方法:我們是第一個開源基於 DiT、類似 Veo-3 的聯合視聽生成模型。
Matrix-3D:可探索的3D 世界
相較於最先進的 360 度影片生成方法,Matrix-3D 在全景影片的視覺品質與合理幾何結構上更優越。同時,在視覺品質與相機可控性上,也超越先前的相機控制影片生成方法。廣泛實驗證明其在全景影片生成與 3D 世界生成上的最先進效能。香港科技大學(廣州分校)有份參預!
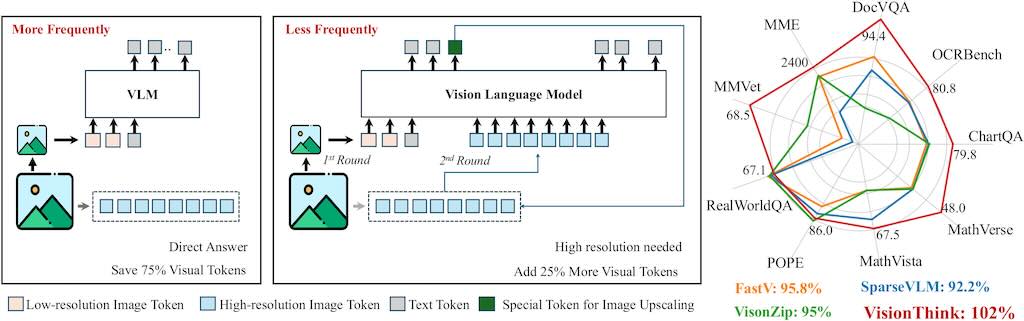
VisionThink 智慧高效視覺語言模型
VisionThink 利用強化學習自主學習減少視覺 token。與傳統的高效 VLM 方法相比,這方法在
微粒度基準測試(例如涉及 OCR 相關任務的基準測試)上取得了顯著的提升。
由香港中文大學,香港大學,科技大學大聯合開發
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning

MultiTalk 音訊驅動生成多人對話影片
由音訊驅動的人體動畫技術,以面部動作同步且畫面吸睛的能力,已經有很顯著的進步。然而,現有的方法大多專注於單人動畫,難以處理多路音訊輸入,也因此常發生音訊與人物無法正確配對的問題。
MultiTalk 為了克服這些挑戰,提出了一項新任務:多人對話影片生成,並引入了一個名為 MultiTalk 的新框架。這個框架專為解決多人生成過程中的難題而設計。具體來說,在處理音訊輸入時,我們研究了多種方案,並提出了一種**標籤旋轉位置嵌入(L-RoPE)**的方法,來解決音訊與人物配對不正確的問題。香港科技大學數學與數學研究中心及電子與電腦工程系有份參與。
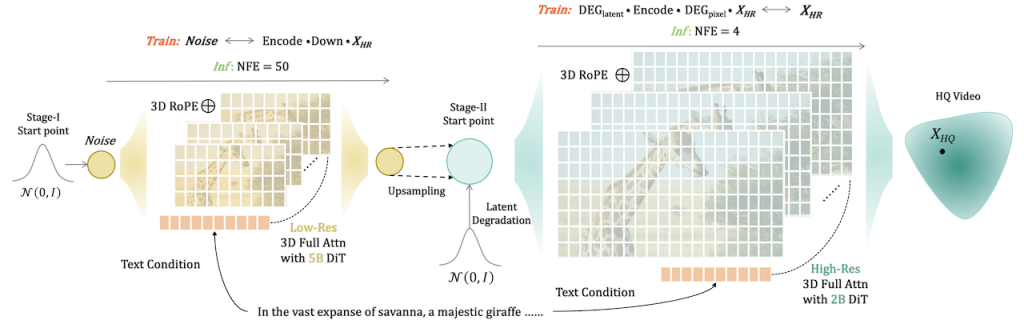
FlashVideo 高速生成高解像度影片
FlashVideo 由香港大學、香港科技大學及 ByteDance 聯合開發,你只需要準備一張或者幾張參考圖片,加上文字提示詞,就可以生成高解像度的影片。過程主要分為兩部份,第一部分是優先處理提示詞,同時以低解像度處理圖片,減少 DIT 的運算時間。第二部分會建立低解像度和高解像度之間的匹配。結果能夠以高速生成 1 0 8 0 P 的高清影片。[DiT] Diffusion Transformer | [NFE ] Number of Function Evaluations
MagicQuill 安裝詳細教學
Step-by-Step: Install MagicQuill and Transform Your Edits Today!

MagicQuill 智慧型互動圖像編輯系統
又一國內手足大作 ! 香港科大有份幫手!開源並已經可以下載。
MagicQuill demo video
