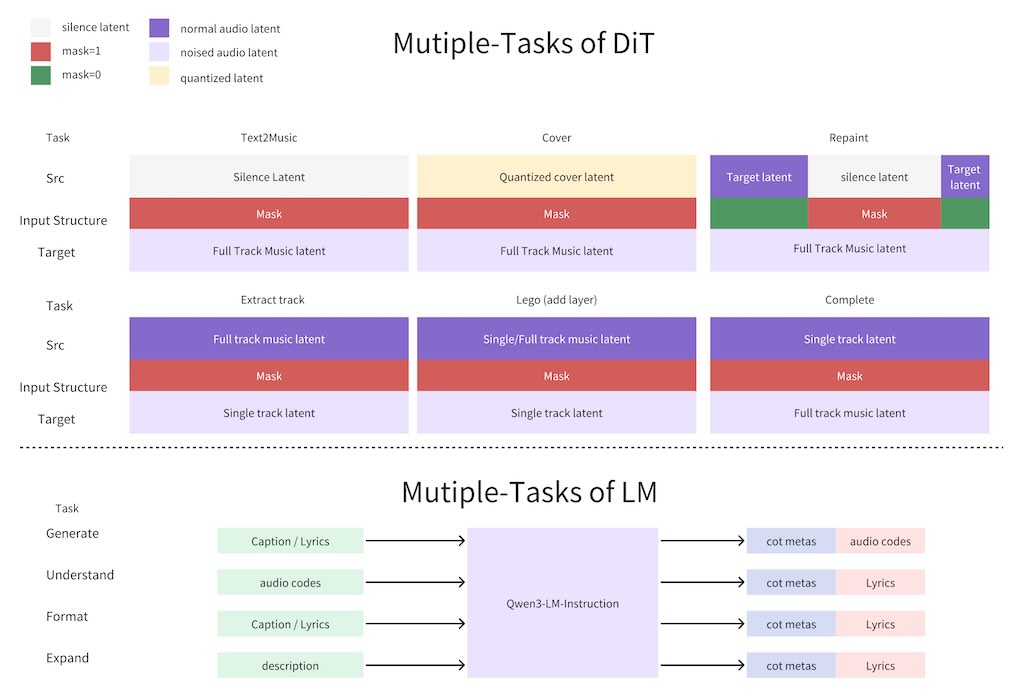
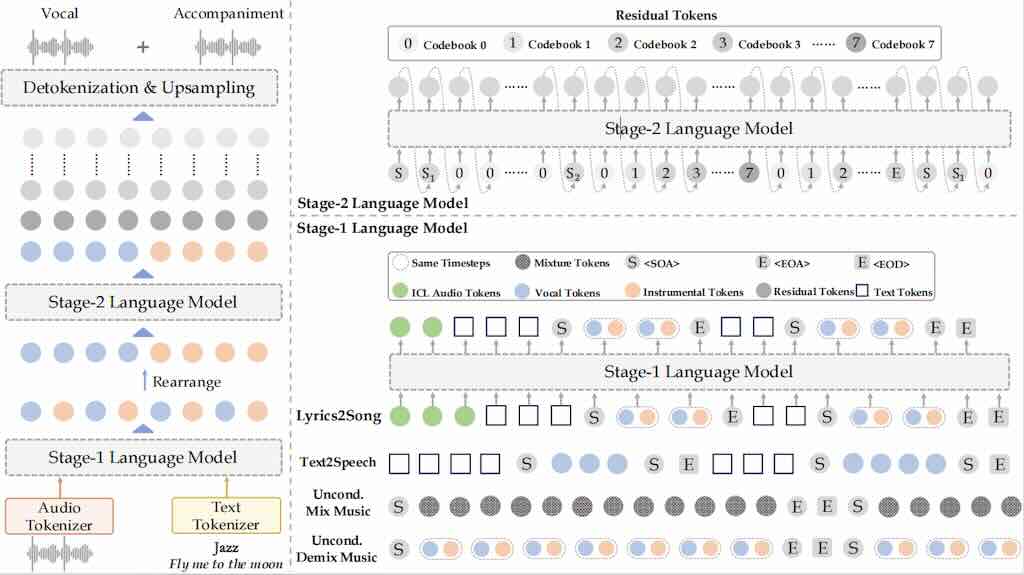
ACE-Step v1.5 是一款高效的開源音樂基礎模型,可將商業級音樂生成功能帶到消費級硬體平台。在常用的評估指標上,ACE-Step v1.5 的音質超越了大多數商業音樂模型,同時速度極快——在 A100 上生成一首完整歌曲不到 2 秒,在 RTX 3090 上不到 10 秒。該模型可在本地運行,僅需不到 4GB 的顯存,並支援輕量級個人化:用戶只需幾首歌曲即可訓練 LoRa 來捕捉自己的音樂風格。實測結果:
(主歌1)
霓虹閃爍的訊號裡,我聽見你呼吸的頻率。數位心跳對齊節拍,在光的碎片裡相遇。
(Pre‑Chorus)
電流穿過沉默的夜,你的笑是程式裡的解。我追著節奏不回頭,感覺像永遠不會舊。
(副歌)
一起在AI夢裡跳,節拍讓我們燃燒。
電子浪潮衝破訊號,讓心越飄越高。
(橋段)
每一聲呼吸都在閃耀,每一行代碼都是心跳。你在那螢光雲端微笑,我在夢境裡呼喊你的名字。
(尾聲)
不論是現實或訊號,我們在節拍裡擁抱。夜的盡頭沒有停靠,只剩我們一起奔跑。