Qwen3‑TTS 由阿里雲的 Qwen 團隊開發的開源語音合成系列模型,專注於提供穩定、富有表現力,且能即時生成語音的功能。整個專案的核心目的在於讓開發者與使用者能夠自由設計語音、快速複製已有聲音,並且能根據指令調整語調、情感與說話速度。相較於市面上其他解決方案,Qwen3‑TTS 同時支援十種主要語言以及多種方言音型,涵蓋中文、英文、日文、韓文、德文、法文、俄文、葡文、西文、意譲等,能讓應用跨語系、跨文化的需求更容易實現。
在技術架構上,Qwen3‑TTS 研發了自己的 Qwen3‑TTS‑Tokeniser‑12Hz 編碼器,這個編碼器能把音訊壓縮成 12.5 Hz 的多本級碼,既保留語义內容,也捕捉細節的聲音特徵。這種設計讓模型在合成音訊時可以使用較輕量的因果卷積網路直接重建波形,降低了運算成本與延遲。相較於傳統的「語言模型+DiT」流程,Qwen3‑TTS 完全貫通端到端的離散多本碼結構,省去了資訊瓶頸與串聯錯誤的問題,提升了整體的生成效率與品質。
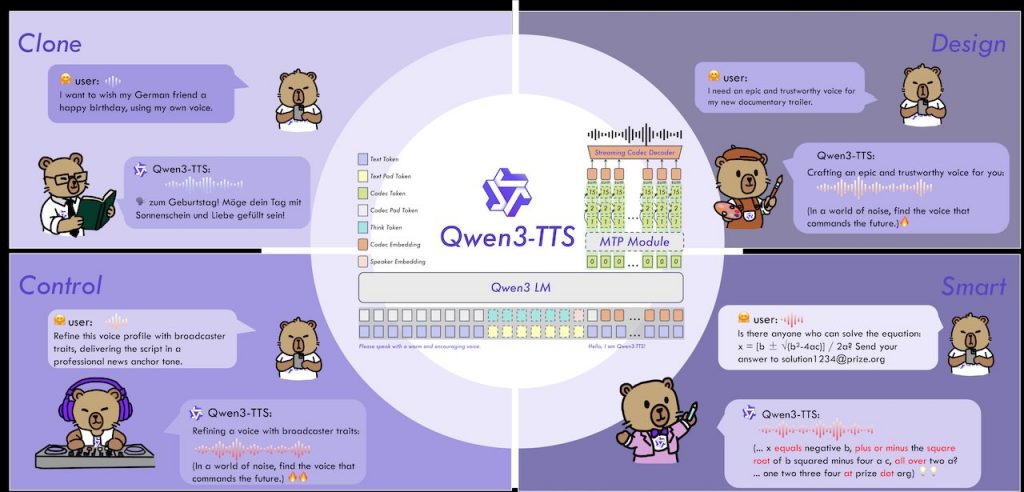
模型本身分為四個主要版本,分別是 1.7 B 以及 0.6 B 兩個大小的基礎模型、以及兩個具備語音設計與客製音色功能的變體。小型版(0.6 B)版的模型在三秒內即可完成從使用者提供的音檔進行快速複製,亦可作為微調(Fine‑Tuning)其他模型的起點;較大的 1.7 B 版則在保留上述功能的同時,提供更多語音樣式與更細膩的情感控制。所有模型都已發布在 GitHub 與 ModelScope 平台,並以 Apache‑2.0 授權,讓社群可自由使用、修改。
開發者只需要安裝 qwen‑tts 套件或使用 vLLM 等推理框架,就能自動下載對應的權重模型。若網路環境較為受限,官方提供了手動下載的指令,可讓使用者把模型權重下載到本機資料夾。更重要的是,Qwen3‑TTS 具備即時流式合成的能力,只要輸入一個字符,就能在 97 毫秒以內產出第一段語音,這使得它非常適合即時對話、虛擬助理或直播互動等需要低延遲的應用情境。模型同時支援多種語音控制方式,例如依照文字說明生成特定音色、根據自然語言描述調整語調與情感,甚至在同一段文字中混合多種音色,形成獨特的聲音組合。
總體而言,Qwen3‑TTS 不僅提供高品質的語音合成,更在多語系支援、流式生成、指令式語音控制與開源授權上提供了完整且可直接使用的解決方案。無論是想要在產品中加入自然的語音回覆、想要快速製作示範音檔、或是需要進行語音克隆與客製化設計的研究者,都能從這個開源項目中快速取得所需的工具與模型,並且能輕鬆將其整合到自己的開發流程中。