相較於最先進的 360 度影片生成方法,Matrix-3D 在全景影片的視覺品質與合理幾何結構上更優越。同時,在視覺品質與相機可控性上,也超越先前的相機控制影片生成方法。廣泛實驗證明其在全景影片生成與 3D 世界生成上的最先進效能。香港科技大學(廣州分校)有份參預!
Qwen-Image 的 LoRA 訓練
Train a Qwen-Image LoRA on 24GB VRAM With AI Toolkit

影片主要介紹如何使用 Ostris AI 開發的 AI Toolkit,在僅有 24 GB VRAM 的 RTX 4090 或 3090 GPU 上,訓練一個基於 Qwen-Image 模型的 LoRA(Low-Rank Adaptation)風格模型。Qwen-Image 是一個 20 億參數的巨型模型,通常需要更高規格的硬體(如 32 GB VRAM 的 RTX 5090),但作者透過創新技術(如量化與 Accuracy Recovery Adapter)實現了在消費級 GPU 上的訓練。影片強調這是對先前影片的延續,先前影片曾在 5090 上使用 6-bit 量化訓練角色 LoRA,而本次聚焦於更常見的 24 GB VRAM 硬體。
Media Services Setup

LongVie – 可控超長影片生成
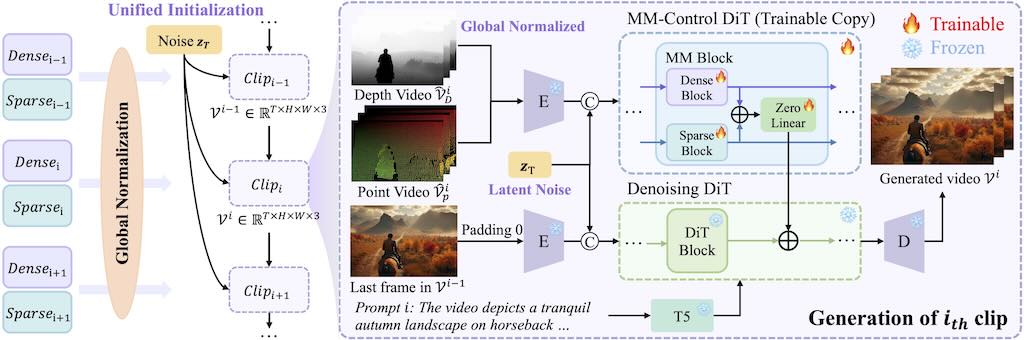
可控的超長影片生成是一項基礎但具有挑戰性的任務,因為現有的方法雖然對短片段有效,但由於時間不一致和視覺品質下降等問題而難以擴展。
LongVie 的核心設計可確保時間一致性:
1)統一雜訊初始化策略,在各個片段之間保持一致的生成;
2)全域控制訊號歸一化,可在整個視訊的控制空間中強制對齊。為了減輕視覺品質下降,LongVie 採用密集(例如深度圖)和稀疏(例如關鍵點)控制訊號,並輔以一種退化感知訓練策略,可以自適應地平衡模態貢獻以保持視覺品質。
OpenAI 的開放權重模型 gpt-oss 系列
pyvideotrans 指南
【2025】别再“啃生肉”了!免费开源!这个AI视频翻译神器,一键搞定字幕&配音,让外语视频秒变“中文版”!| pyvideotrans教程

JAM – 基於串流的微型歌曲生成器
近年來,擴散模型和流匹配模型徹底改變了文字轉音頻的自動生成。這些模型產生高品質、忠實的音訊輸出的能力日益增強,能夠捕捉語音和聲學事件。然而,在主要涉及音樂和歌曲的創意音訊生成方面,仍有很大改進空間。近期推出的開放式歌詞轉歌曲模型,例如 DiffRhythm、ACE-Step 和 LeVo,已經為娛樂用途的自動歌曲生成樹立了可接受的標準。然而,這些模型缺乏音樂家在工作流程中經常需要的細粒度的詞級控制能力。他們基於流匹配的 JAM 是首次在歌曲生成中引入詞級時間和時長控制,從而實現細致度的人聲控制。為了提高生成的歌曲質量,使其更符合人類的偏好,我們透過直接偏好優化 (Direct Preference Optimization) 實現了美學一致性,該方法使用合成資料集迭代地優化模型,從而無需手動進行資料註釋。此外,他們旨在透過公開評估資料集 JAME 來標準化此類歌詞到歌曲模型的評估。他們證明,JAM 在音樂特定屬性方面的表現優於現有模型。
JAM 建構於一個緊湊的 530M 參數架構之上,並以 16 個 LLaMA 風格的 Transformer 層作為 Diffusion Transformer (DiT) 的主幹,從而實現了音樂家在工作流程中所需的精準人聲控制。與先前的模型不同,JAM 提供詞級和音素級的時序控制,使音樂家能夠指定每個人聲的精確位置,從而提高節奏的靈活性和表現力。

Qwen3-Coder: 超強 Coding 代理
Qwen3-Coder 是我們迄今為止最具代理性的程式碼模型。 Qwen3-Coder 提供多種規模,首先是其最強大的版本:Qwen3-Coder-480B-A35B-Instruct。這是一個擁有 480B 參數的混合專家模型,其中擁有 35B 個有效參數,原生支援 256K 個 token 的上下文長度,並透過外推方法支援 1M 個 token 的上下文長度,在編碼和代理任務中均創下了新的最高紀錄,與 Claude Sonnet 4 相當。
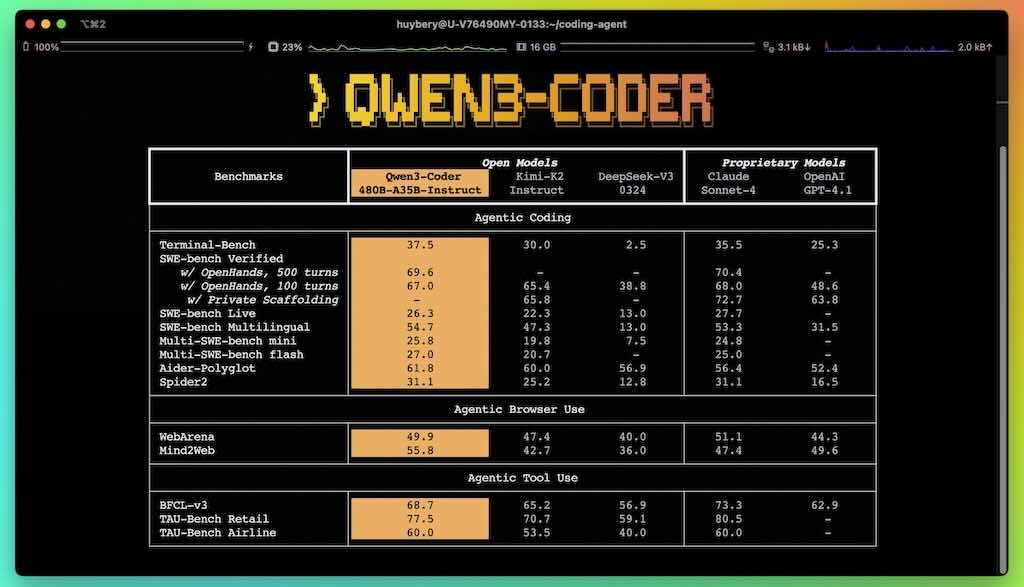
除此,Qwen 開源了一款用於代理程式編碼的命令列工具:Qwen Code。 Qwen Code 是從 Gemini Code 衍生而來,並經過了調整,添加了自訂提示符和函數呼叫協議,從而充分發揮 Qwen3-Coder 在代理程式編碼任務中的強大功能。
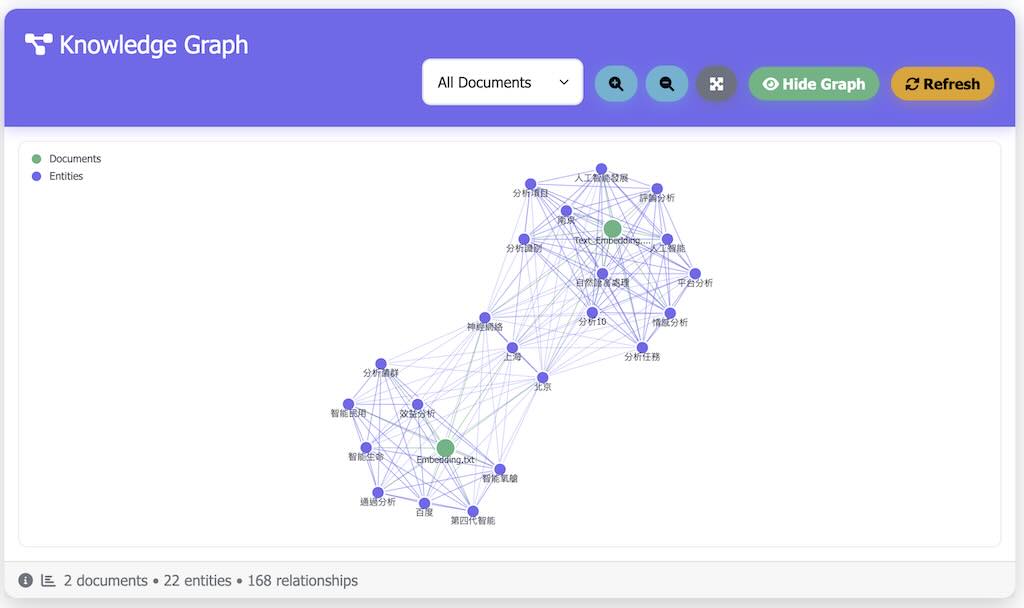
Knowledge Graph RAG 知識圖譜問答系統
Knowledge Graph RAG 是個現代、響應迅速,基於 Web 的知識圖譜 RAG 應用程序,可以回答有關您上傳的文檔的問題、可視化知識圖譜並管理專用的關鍵字。
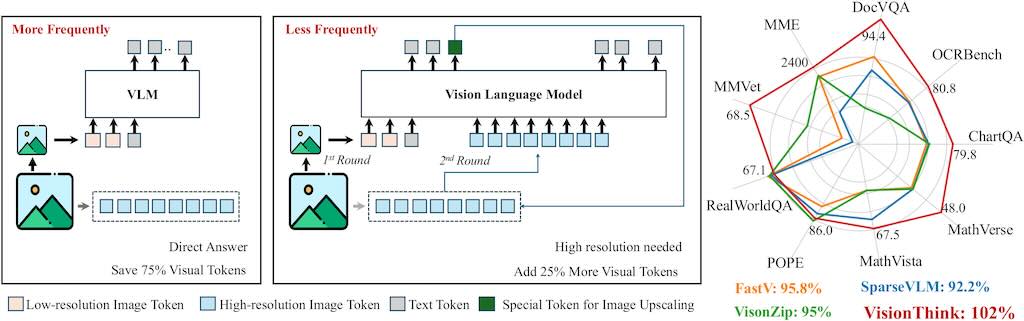
VisionThink 智慧高效視覺語言模型
VisionThink 利用強化學習自主學習減少視覺 token。與傳統的高效 VLM 方法相比,這方法在
微粒度基準測試(例如涉及 OCR 相關任務的基準測試)上取得了顯著的提升。
由香港中文大學,香港大學,科技大學大聯合開發
VisionThink: Smart and Efficient Vision Language Model via Reinforcement Learning
