Local Talking LLM - Jarvis mark1 Speech | Whisper STT - Ollama - Chatterbox TTS

- 🎯語音克隆:只需一段簡短的音訊樣本即可克隆任何聲音
- 🎭情緒控制:調整回應的情緒表達
- 🚀效能更佳:0.5B 參數模型,推理速度更快
- 💧音頻浮水印:內建神經浮水印,確保真實性
Story2Board 是個無需訓練的框架,用於從自然語言中生成富有表現力的故事板。目標是將敘事呈現為一系列連貫的故事板面板——每個面板描繪不同的場景,同時保留主要角色的身份和外觀。

Archon 是一款為所有 AI 編程人量身打造,強調知識檢索、專案協作、即時上下文整合的開源編程操作系統,無論是個人或團隊都可極大提升 AI coding 助手的效能、協同與上下文管理力,非常適合想全面解鎖 AI 編程革命的人嘗試使用。

Matrix-Game 2.0 是一套高效、強大的互動世界生成系統,專注於視覺與行動融合,能夠在多種遊戲場景下生成高質量、流暢並可交互的視頻內容,領先於現有主流方案,適合用於前沿AI遊戲和虛擬世界研究。主要由Skywork AI團隊開發。

Omni-Effects 是一套針對視覺特效(VFX)生成的統一框架,主打多效果合成和空間可控性。這項技術突破了以往僅能針對單一特效單獨訓練(如 per-effect LoRA)的限制,可同時在指定區域生成多種特效,極大拓展了在影視製作及創意領域的應用可能性。
框架的核心包含兩項關鍵創新:(1) 基於 LoRA 的混合專家 (LoRA-MoE),將多種效果整合到統一模型中,同時有效地減少跨任務幹擾。 (2) 空間感知提示 (SAP)將空間遮罩資訊合併到文字標記中,從而實現精確的空間控制。

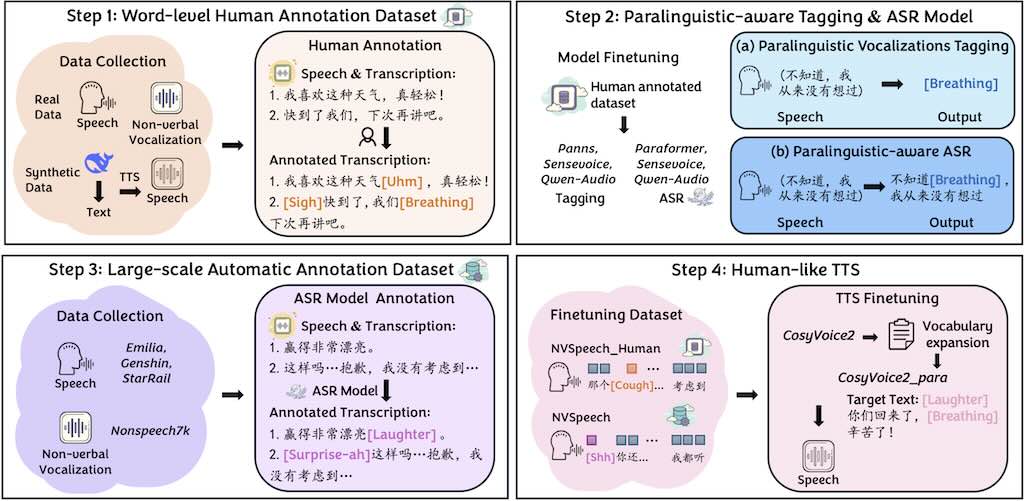
NVSpeech 用於處理副語言聲音(paralinguistic vocalizations),包括非語言聲音(如笑聲、呼吸)和詞彙化插入語(如「uhm」、「oh」)。這些元素在自然對話中至關重要,能傳達情感、意圖和互動線索,但傳統自動語音辨識(ASR)和文字轉語音(TTS)系統往往忽略它們。
相較於最先進的 360 度影片生成方法,Matrix-3D 在全景影片的視覺品質與合理幾何結構上更優越。同時,在視覺品質與相機可控性上,也超越先前的相機控制影片生成方法。廣泛實驗證明其在全景影片生成與 3D 世界生成上的最先進效能。香港科技大學(廣州分校)有份參預!

影片主要介紹如何使用 Ostris AI 開發的 AI Toolkit,在僅有 24 GB VRAM 的 RTX 4090 或 3090 GPU 上,訓練一個基於 Qwen-Image 模型的 LoRA(Low-Rank Adaptation)風格模型。Qwen-Image 是一個 20 億參數的巨型模型,通常需要更高規格的硬體(如 32 GB VRAM 的 RTX 5090),但作者透過創新技術(如量化與 Accuracy Recovery Adapter)實現了在消費級 GPU 上的訓練。影片強調這是對先前影片的延續,先前影片曾在 5090 上使用 6-bit 量化訓練角色 LoRA,而本次聚焦於更常見的 24 GB VRAM 硬體。
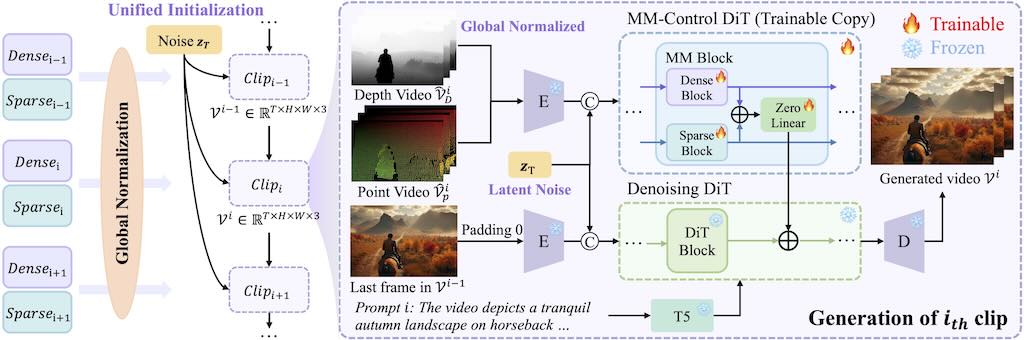
可控的超長影片生成是一項基礎但具有挑戰性的任務,因為現有的方法雖然對短片段有效,但由於時間不一致和視覺品質下降等問題而難以擴展。
LongVie 的核心設計可確保時間一致性:
1)統一雜訊初始化策略,在各個片段之間保持一致的生成;
2)全域控制訊號歸一化,可在整個視訊的控制空間中強制對齊。為了減輕視覺品質下降,LongVie 採用密集(例如深度圖)和稀疏(例如關鍵點)控制訊號,並輔以一種退化感知訓練策略,可以自適應地平衡模態貢獻以保持視覺品質。