视频也能P Comfyui最强视频工作流三连发

Google 在最新的官方開發者更新中宣布,Gemini CLI v0.9.0 現已支援完整的「互動式終端命令」體驗,這是該工具迄今最大的架構升級之一。
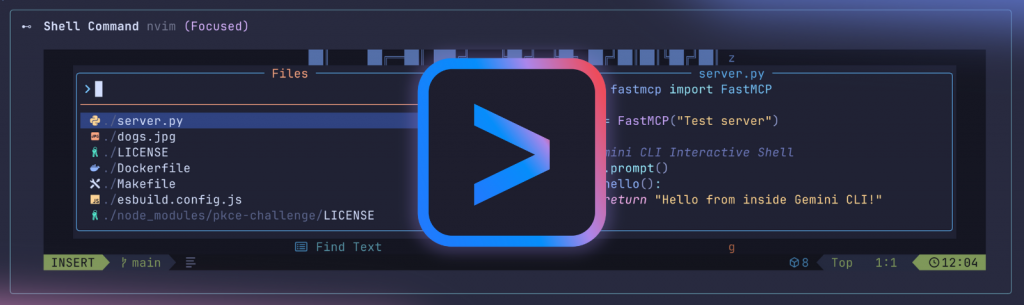
互動式命令支援:使用者現在可以直接在 Gemini CLI 內運行 vim 編輯器、top 系統監控、
git rebase -i 等互動性命令,而無需離開 CLI 環境。
Pseudo-terminal(PTY) 整合:CLI 現在透過 node-pty 函式庫啟動虛擬終端(pseudo-terminal)進程,讓作業系統識別該 session 為終端機應用,使應用可如原生環境般運行。
即時輸出串流:新增的 serializer 元件能持續擷取虛擬終端的畫面快照(包含文字、顏色、游標位置等),並即時串流回使用者端,呈現如「直播」般的互動視覺效果。
雙向通訊能力:CLI 支援將鍵盤輸入即時傳送至背景進程,並能隨視窗大小自動調整顯示區域,就像原生 shell 一樣。
增強的色彩輸出:輸出渲染引擎改進,能正確顯示彩色終端輸出,呈現更完整的命令列視覺效果。
快捷鍵焦點切換:可使用 Ctrl + F 專注於互動終端視窗。
Gemini CLI v0.9.0 起預設啟用此互動式 shell,可透過下列指令升級至最新版本:
npm install -g @google/gemini-cli@latest這項更新的核心在於引入 pseudo-terminal (PTY) 與 即時序列化/串流處理機制,構成完整的「可觀察、可輸入、可重繪」終端環境,使 Google 的 Gemini CLI 同時具備 AI 輔助與原生 shell 操作體驗。
OpenSpec 是一套專為 AI 助手而設計的規格驅動開發(Spec-driven Development, SDD)工具,主要用於 AI 協同開發時,提前鎖定功能需求和規格,避免 AI 直接從對話生成不可控的實作。

Ovi 使用了專屬預訓練 5B 音頻分支,架構設計類似 WAN 2.2 5B,同時提供了 1B 融合分支,支持純文本或文本+圖片輸入,自動生成視頻、對嘴音頻,以及匹配場景的背景音效和音樂。



近期的影片生成模型已能產生流暢且具視覺吸引力的影片片段,但在結合複雜動態與連貫的事件因果上仍然面臨挑戰。如何準確建模隨時間變化的視覺結果與狀態,依然是核心難題。
相對而言,大型語言與多模態模型(如 GPT-4o)展現出強大的視覺狀態推理與未來預測能力。為了結合這些優勢,VChain 是一種新穎的「推理時間視覺思維鏈」框架。VChain 將多模態模型的視覺推理信號,注入影片生成過程中,以增強生成模型的推理一致性。
具體而言,VChain 包含一個專用管線,利用大型多模態模型生成一組稀疏的關鍵幀作為事件快照,並在這些關鍵時刻指導預訓練影片生成器進行稀疏推理時間調整。這種設計使調整過程高效、開銷極低,且無需密集監督。

Paper2Video 能從輸入的論文(LaTeX源碼)、一張圖片和一段音頻,生成完整的學術報告視頻。集成了幻燈片生成、字幕生成、游標定位、語音合成、講者視頻渲染等多模態子模塊,實現一條龍的演示視頻製作流程。支持並行處理以提升視頻生成效率,推薦GPU為NVIDIA A6000(48G顯存)及以上。
需要設定 GPT-4.1 或 Gemini2.5-Pro 等大型語言模型 API Key,支持本地 Qwen 模型。
musubi-tuner 提供使用 HunyuanVideo、Wan2.1/2.2、FramePack、FLUX.1 Kontext 和 Qwen-Image 架構訓練 LoRA(低秩自適應)模型的腳本。

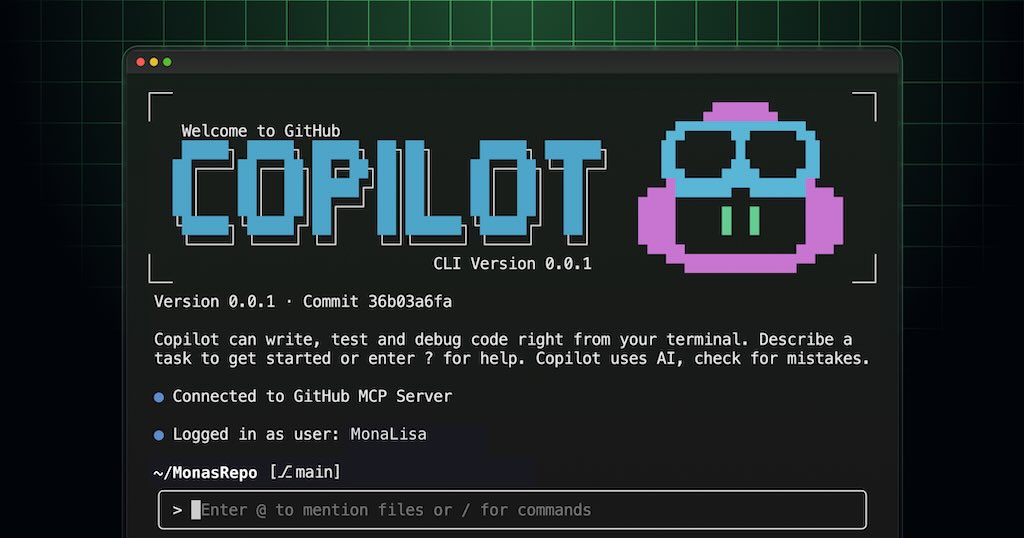
GitHub Copilot 編碼代理的強大功能直接帶到您的終端。透過 GitHub Copilot CLI,您可以在本地與能夠理解您的程式碼和 GitHub 上下文的 AI 代理程式同步工作。
Chrome MCP 伺服器是一款基於 Chrome 擴充功能的
模型上下文協定 (MCP) 伺服器,它將您的 Chrome 瀏覽器功能開放給 Claude 等 AI 助手,從而實現複雜的瀏覽器自動化、內容分析和語義搜尋。與傳統的瀏覽器自動化工具(例如 Playwright)不同,
Chrome MCP 伺服器直接使用您日常使用的 Chrome 瀏覽器,利用現有的使用者習慣、配置和登入狀態,讓各種大型模型或聊天機器人控制您的瀏覽器,真正成為您的日常助理。

