影片將一步步帶你上手 PersonaLive,教你如何使用 AI 即時角色變換,在直播或影片中實現即時變身效果,全流程免費。
用 AI 即時變身女神|免費

影片將一步步帶你上手 PersonaLive,教你如何使用 AI 即時角色變換,在直播或影片中實現即時變身效果,全流程免費。
在本機用 ComfyUI 跑 Qwen Image Edit 2511,包含 BF16、FP8 和 GGUF 量化版本,以及 Lightning 4‑step LoRA 的完整實戰示範。

Saber 由 Meta 開發,是一個「只用影片+文字資料就能做參考到影片生成」的零訓練框架,輸入幾張參考圖和一段文字,就能生出既長得像參考主體、又符合文字描述的影片。(訓練和推理程式碼整理完畢後將會發布,敬請期待。)
一般 R2V (Reference to video)要「參考圖+影片+文字」三元組,資料很難蒐集也不易擴充。Saber 完全不收這種三元組,只吃大規模「影片+文字」。
訓練時,它把同一支影片中的某些幀「當成參考圖」,再加上遮罩,讓模型自己學會:怎麼在生成影片時保持主角長相一致、又能跟文字對齊。
技術做法(直覺理解)
遮罩訓練:從影片抽幀,套上各種形狀與面積比例的二值遮罩,當作「動態參考圖庫」,讓模型看到超多種類的參考條件。
遮罩增強:對圖和遮罩一起做旋轉、縮放、平移、翻轉等變形,打亂空間對齊,避免模型學到「直接把參考貼上去」的作弊路線。
模型與注意力設計
影片與參考圖先丟進 VAE 變成 latent,然後在時間維度把「影片 latent」和「參考 latent」串起來,一起丟進 Transformer 做擴散。參考 latent 不加噪音,保持條件乾淨。
自注意力裡用「注意力遮罩」限制:影片 token 可以互相看、也能看參考,但參考 token 只能看自己有效的前景區域,避免注意到背景干擾。
推論流程與能力
推論時,會先用預訓練分割器(例如 BiRefNet)把參考圖的人或物分出來;如果想要用整張背景當條件,就不做分割而用全 1 遮罩。
Saber 可以吃多張參考,支援多視角同一主體,也能多主體;在 OpenS2V-Eval 基準上,主體一致性與整體品質都比 Phantom、VACE、Kling1.6 等專門 R2V 模型更好。
限制與展望
當參考圖過多(例如 12 張)時,模型有機會「崩壞」,把不同參考碎片硬湊在同一畫面,語義整合不足。
目前重心在身份保留與視覺自然度,對非常細緻的動作控制或複雜時序一致性仍不完美,未來方向包括更聰明地整合大量參考及更可控的動作與真實感。
官方 GitHub 儲存庫為 https://github.com/franciszzj/Saber,提供模型細節與訓練資訊。 論文《Scaling Zero-Shot Reference-to-Video Generation》發布於 arXiv (2512.06905)。
Light-X 是個視訊生成框架,它能夠從視訊中實現可控渲染,並同時控制視角和光照。
Light-X 提出一種解耦設計,將幾何形狀和光照信號解耦:幾何形狀和運動通過沿用戶定義的相機軌跡投影的動態點雲來捕獲,而光照線索則由始終投影到相同幾何形狀的重新光照幀提供。這些明確的、細粒度的線索能夠有效地解耦,並指導高品質的光照。
為了解決缺乏配對的多視角和多光照視頻的問題,Light-X 引入了Light-Syn,這是一種基於退化和逆映射的流程,它利用自然場景下的單目視頻素材合成訓練對。此策略產生了一個涵蓋靜態、動態和 AI 生成場景的資料集,確保了訓練的穩健性。大量實驗表明,Light-X 在聯合相機光照控制方面優於基線方法,並且在文字和背景兩種條件下均優於以往的視訊重光照方法。
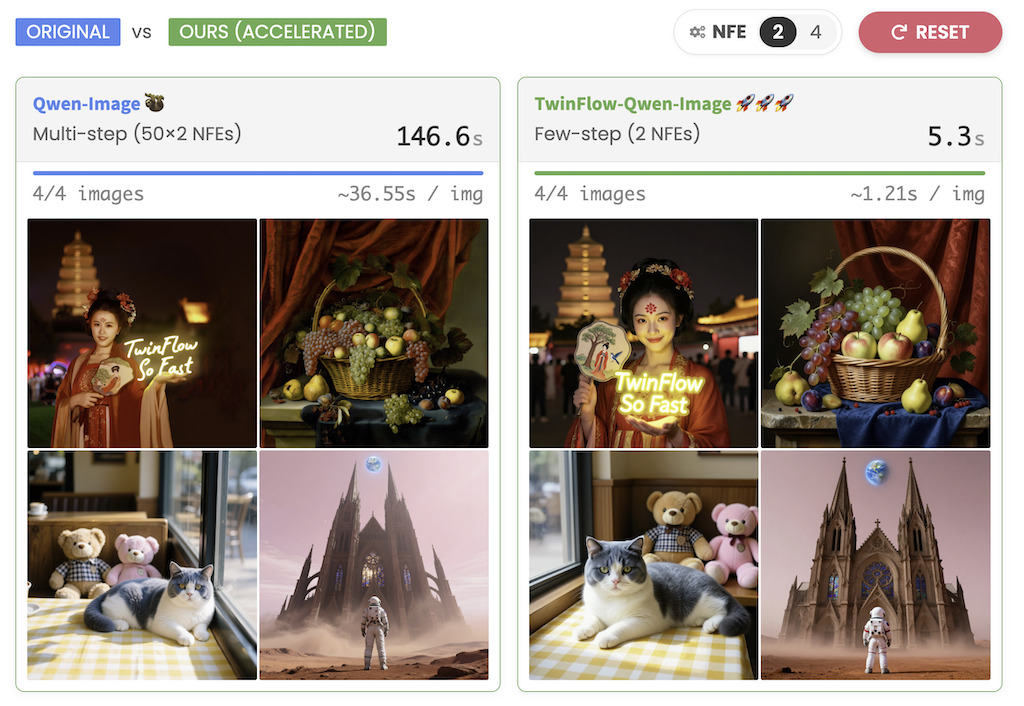
TwinFlow 利用自對抗流實現大型模型的一步生成框架,是一個能夠實現高品質單步和少步生成而不會造成管道臃腫的框架。
值得注意一般大型多模態模型為了取得了驚人的生成能力,代價十分高昂:因為推理效率低。標準的擴散模型和流動匹配模型通常需要50-100 次非特徵提取 (NFE)才能產生一幅影像。
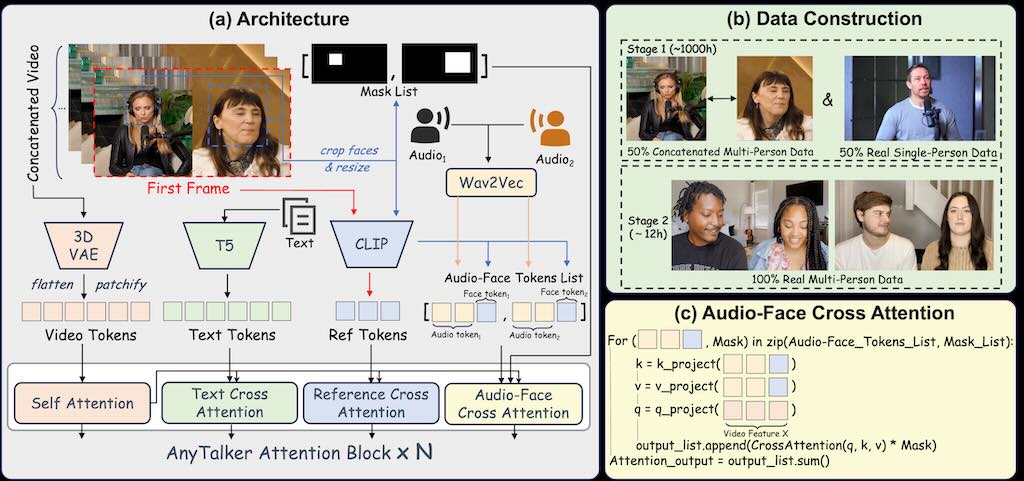
AnyTalker,一個基於音訊的多人對話的開源視訊生成框架。它採用靈活的多流結構,既能擴展身份規模,又能確保身份之間的無縫互動。
Z Image Turbo 支持 ComfyUI,它採用 qwen_3_4b.safetensors 的 Text encoder 及 Flux 1 VAE 。

Z-Image 是一款功能強大且高效的影像生成模型,擁有60 億個參數。目前共有三個版本:
🚀 Z-Image-Turbo – Z-Image 的精簡版,僅需8 次函數評估 (NFE),即可達到甚至超越領先競爭對手的性能。它在企業級 H800 GPU 上可實現⚡️亞秒級推理延遲⚡️,並能輕鬆適配16G 顯存的消費級設備。它在照片級圖像生成、雙語文字渲染(中英文)以及強大的指令執行能力方面表現卓越。
🧱 Z-Image-Base – 未經精簡的基礎模型。透過發布此版本,我們旨在充分釋放社群驅動的微調和自訂開發的潛力。
✍️ Z-Image-Edit – Z-Image 的一個衍生版本,專為影像編輯任務而最佳化。它支援創意圖像到圖像的生成,並具備強大的指令跟隨功能,允許根據自然語言提示進行精確編輯。

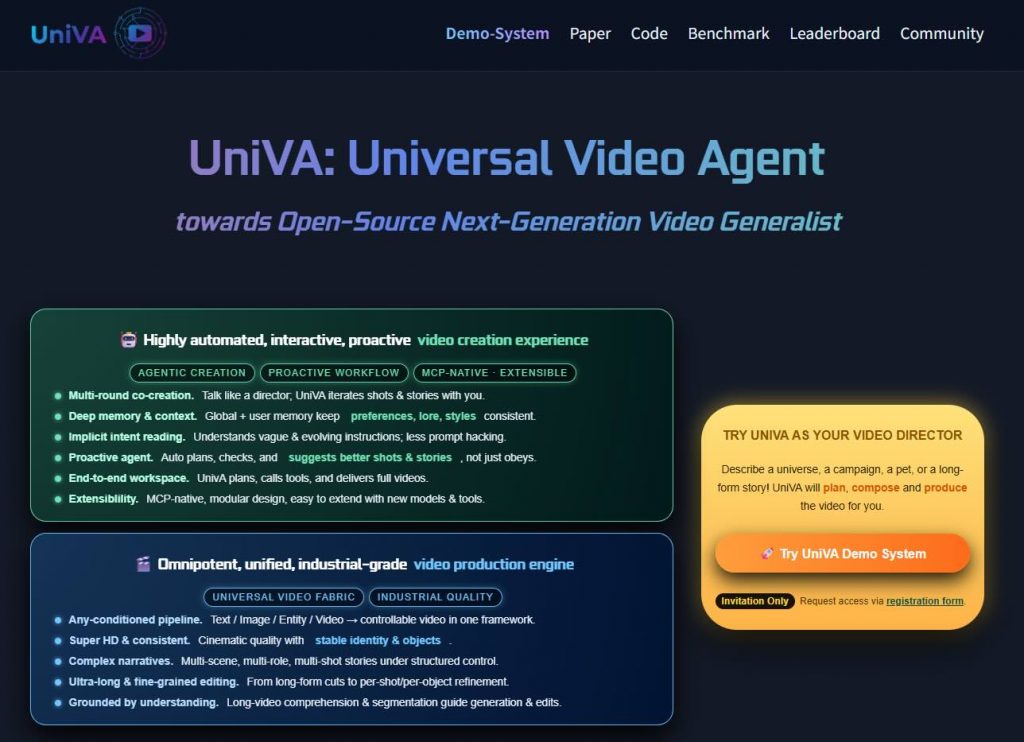
一套開源、多代理的「全能型影片處理框架」UniVA,目的是將影片理解、分割、剪輯與生成等功能統合成自動化且可擴展的工作流程。