LuxTTS 声音克隆 | 1G低显存必备,全系电脑适配,150倍超快速推理,高清晰48KHz声音复刻~

Qwen3‑TTS 由阿里雲的 Qwen 團隊開發的開源語音合成系列模型,專注於提供穩定、富有表現力,且能即時生成語音的功能。整個專案的核心目的在於讓開發者與使用者能夠自由設計語音、快速複製已有聲音,並且能根據指令調整語調、情感與說話速度。相較於市面上其他解決方案,Qwen3‑TTS 同時支援十種主要語言以及多種方言音型,涵蓋中文、英文、日文、韓文、德文、法文、俄文、葡文、西文、意譲等,能讓應用跨語系、跨文化的需求更容易實現。
在技術架構上,Qwen3‑TTS 研發了自己的 Qwen3‑TTS‑Tokeniser‑12Hz 編碼器,這個編碼器能把音訊壓縮成 12.5 Hz 的多本級碼,既保留語义內容,也捕捉細節的聲音特徵。這種設計讓模型在合成音訊時可以使用較輕量的因果卷積網路直接重建波形,降低了運算成本與延遲。相較於傳統的「語言模型+DiT」流程,Qwen3‑TTS 完全貫通端到端的離散多本碼結構,省去了資訊瓶頸與串聯錯誤的問題,提升了整體的生成效率與品質。
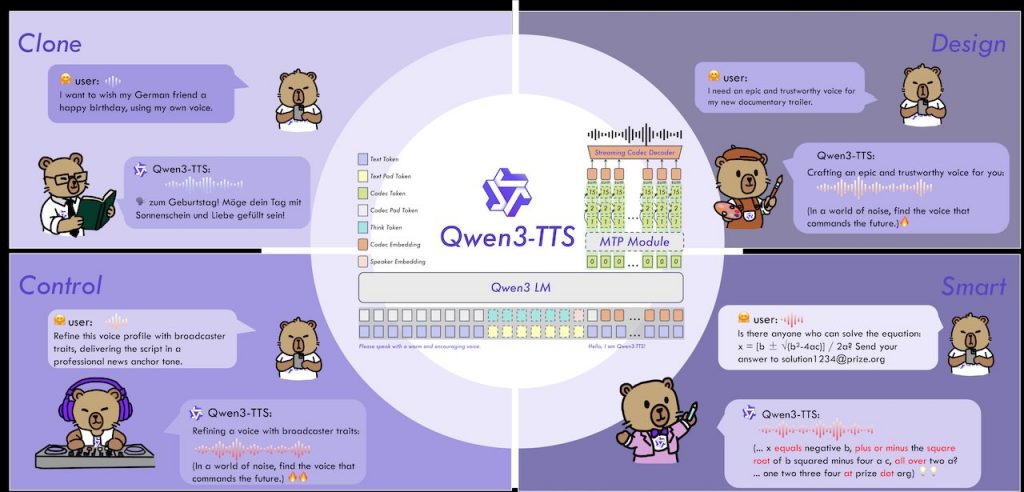
模型本身分為四個主要版本,分別是 1.7 B 以及 0.6 B 兩個大小的基礎模型、以及兩個具備語音設計與客製音色功能的變體。小型版(0.6 B)版的模型在三秒內即可完成從使用者提供的音檔進行快速複製,亦可作為微調(Fine‑Tuning)其他模型的起點;較大的 1.7 B 版則在保留上述功能的同時,提供更多語音樣式與更細膩的情感控制。所有模型都已發布在 GitHub 與 ModelScope 平台,並以 Apache‑2.0 授權,讓社群可自由使用、修改。
開發者只需要安裝 qwen‑tts 套件或使用 vLLM 等推理框架,就能自動下載對應的權重模型。若網路環境較為受限,官方提供了手動下載的指令,可讓使用者把模型權重下載到本機資料夾。更重要的是,Qwen3‑TTS 具備即時流式合成的能力,只要輸入一個字符,就能在 97 毫秒以內產出第一段語音,這使得它非常適合即時對話、虛擬助理或直播互動等需要低延遲的應用情境。模型同時支援多種語音控制方式,例如依照文字說明生成特定音色、根據自然語言描述調整語調與情感,甚至在同一段文字中混合多種音色,形成獨特的聲音組合。
總體而言,Qwen3‑TTS 不僅提供高品質的語音合成,更在多語系支援、流式生成、指令式語音控制與開源授權上提供了完整且可直接使用的解決方案。無論是想要在產品中加入自然的語音回覆、想要快速製作示範音檔、或是需要進行語音克隆與客製化設計的研究者,都能從這個開源項目中快速取得所需的工具與模型,並且能輕鬆將其整合到自己的開發流程中。

PersonaPlex 是一款即時、全雙工的語音對話模型,它透過基於文字的角色提示和基於音訊的語音訓練來實現角色控制。該模型結合了合成對話和真實對話進行訓練,能夠產生自然、低延遲且角色一致的語音互動。 PersonaPlex 是基於 Moshi 架構和權重。

Paper2Video 能從輸入的論文(LaTeX源碼)、一張圖片和一段音頻,生成完整的學術報告視頻。集成了幻燈片生成、字幕生成、游標定位、語音合成、講者視頻渲染等多模態子模塊,實現一條龍的演示視頻製作流程。支持並行處理以提升視頻生成效率,推薦GPU為NVIDIA A6000(48G顯存)及以上。
需要設定 GPT-4.1 或 Gemini2.5-Pro 等大型語言模型 API Key,支持本地 Qwen 模型。
VibeVoice 是一個開源,能將文字內容轉化為自然流暢、多角色對話音訊的框架工具。它擁有充滿情感與生命力的聲音。VibeVoice 不僅僅是一個文字轉語音 (TTS) 模型,它更是一個解決傳統 TTS 系統在可擴展性、說話者一致性及自然輪流對話方面重大挑戰的創新框架,特別適用於生成播客等長篇、多說話者的對話音訊。
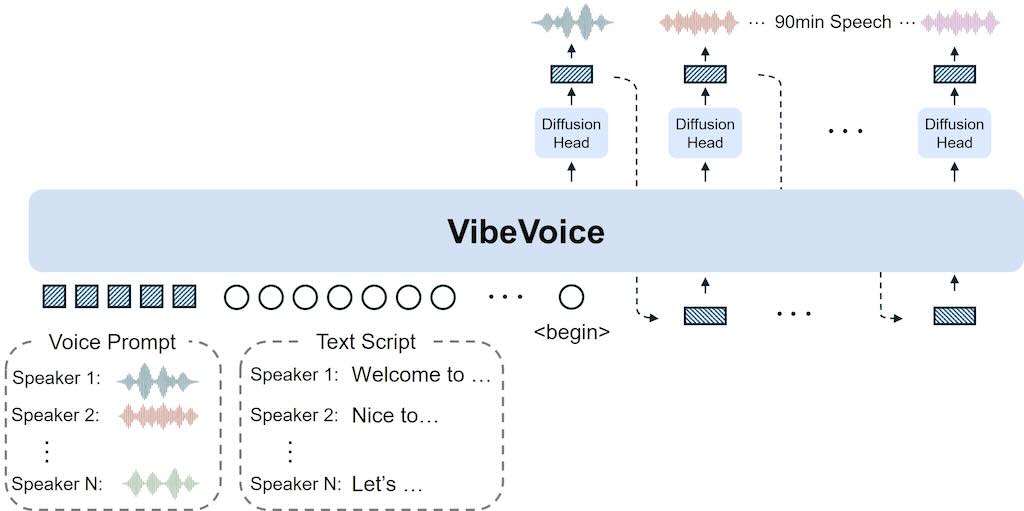
VibeVoice 的核心創新之一,在於其採用了連續語音分詞器(聲學和語義),並以超低 7.5 Hz 的幀率運行。這些分詞器能有效地保留音訊保真度,同時顯著提升處理長序列的計算效率。此外,VibeVoice 採用了「下一詞元擴散」框架,巧妙地利用大型語言模型 (LLM) 來理解文本語境和對話流程,再透過擴散頭生成高保真度的聲學細節。這使得模型能夠合成長達 90 分鐘的語音,並支援多達 4 位不同的說話者,遠超許多先前模型通常僅限於 1-2 位說話者的限制。
(more…)MAI-Voice-1 是一種速度極快的語音生成模型,能夠在單個 GPU 上不到一秒的時間內生成一分鐘的音頻,使其成為當今最高效的語音系統之一。MAI-Voice-1 現已支援我們的 Copilot Daily 和 Podcasts 功能。也在 Copilot Labs 中推出MAI-Voice-1,您可以在那裡試用富有表現力的演講和故事演示。想像一下,只需一個簡單的提示,您就可以創作一個「選擇你自己的冒險」故事,或自訂一個有助於睡眠的引導式冥想。快來嘗試一下吧!
微軟從巨型模型到輕量級智慧,創新雙管齊下。正積極推動其基礎模型(foundation models)的創新,並為此推出了兩款重要的內部開發模型:超大型的 MAI-1,以及輕巧高效的 Phi-3 系列模型,展現了其在AI策略上的深遠佈局。


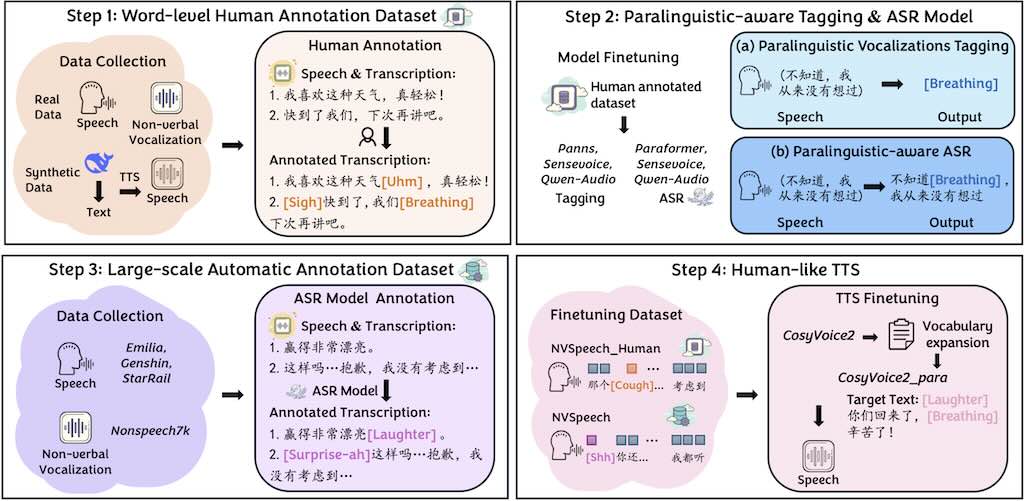
NVSpeech 用於處理副語言聲音(paralinguistic vocalizations),包括非語言聲音(如笑聲、呼吸)和詞彙化插入語(如「uhm」、「oh」)。這些元素在自然對話中至關重要,能傳達情感、意圖和互動線索,但傳統自動語音辨識(ASR)和文字轉語音(TTS)系統往往忽略它們。