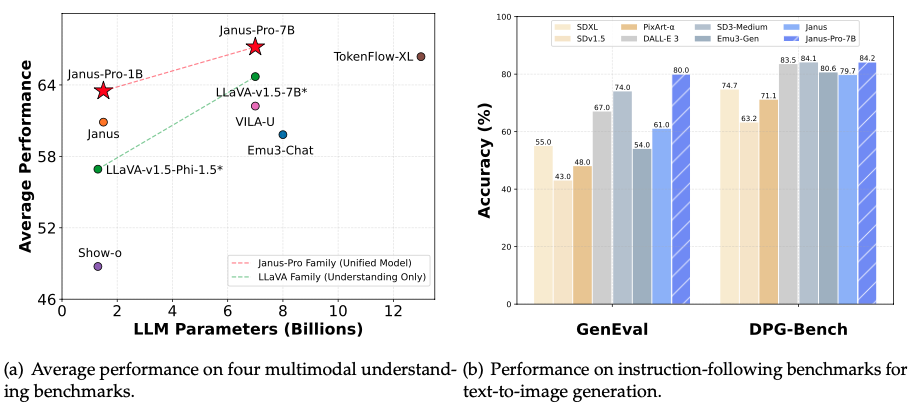
可控的超長影片生成是一項基礎但具有挑戰性的任務,因為現有的方法雖然對短片段有效,但由於時間不一致和視覺品質下降等問題而難以擴展。
LongVie 的核心設計可確保時間一致性:
1)統一雜訊初始化策略,在各個片段之間保持一致的生成;
2)全域控制訊號歸一化,可在整個視訊的控制空間中強制對齊。為了減輕視覺品質下降,LongVie 採用密集(例如深度圖)和稀疏(例如關鍵點)控制訊號,並輔以一種退化感知訓練策略,可以自適應地平衡模態貢獻以保持視覺品質。
可控的超長影片生成是一項基礎但具有挑戰性的任務,因為現有的方法雖然對短片段有效,但由於時間不一致和視覺品質下降等問題而難以擴展。
LongVie 的核心設計可確保時間一致性:
1)統一雜訊初始化策略,在各個片段之間保持一致的生成;
2)全域控制訊號歸一化,可在整個視訊的控制空間中強制對齊。為了減輕視覺品質下降,LongVie 採用密集(例如深度圖)和稀疏(例如關鍵點)控制訊號,並輔以一種退化感知訓練策略,可以自適應地平衡模態貢獻以保持視覺品質。
這個教程介紹如何使用 Flux Kontext 和 VACE 第一幀/最後一幀在 ComfyUI 中創建基於關鍵幀的高級動畫!Kontext 瞭解完整的圖像上下文,而 VACE 允許在起始幀和完全不同的最終姿勢或角色之間無縫移動。無論您是將一個人變形為另一個人,還是為角色的姿勢製作跨時間的動畫,這都是 AI 視頻生成的一個突破。

由音訊驅動的人體動畫技術,以面部動作同步且畫面吸睛的能力,已經有很顯著的進步。然而,現有的方法大多專注於單人動畫,難以處理多路音訊輸入,也因此常發生音訊與人物無法正確配對的問題。
MultiTalk 為了克服這些挑戰,提出了一項新任務:多人對話影片生成,並引入了一個名為 MultiTalk 的新框架。這個框架專為解決多人生成過程中的難題而設計。具體來說,在處理音訊輸入時,我們研究了多種方案,並提出了一種**標籤旋轉位置嵌入(L-RoPE)**的方法,來解決音訊與人物配對不正確的問題。香港科技大學數學與數學研究中心及電子與電腦工程系有份參與。
NVIDIA 與 Black Forest Labs 合作,使用
NVIDIA TensorRT軟體開發套件和量化技術針對
NVIDIA RTX GPU 優化 FLUX.1 Kontext [dev],
從而以更低的 VRAM 要求提供更快的推理速度。
LTX-Video 是第一個基於 DiT 的視訊生成模型,可以即時產生高品質的視訊。它可以以 1216×704 的分辨率生成 30 FPS 的視頻,比觀看這些視頻的速度還快。該模型在多樣化影片的大規模資料集上進行訓練,可以產生具有逼真和多樣化內容的高解析度影片。模型支援文字轉圖像、圖像轉影片、基於關鍵影格的動畫、影片擴充(正向和反向)、影片轉影片以及這些功能的任意組合。




FramePack 是一種新的視頻擴散設計,用壓縮上下文令工作量不會隨著影片的長度而增加,只需一張圖片,就可以令你的 6GB vRAM 的電腦透過 13B 模型生成每秒 30 格影片的 60 秒影片。而用 RTX 4090 的話,最快速度為每格 1.5 秒。
作者 Lvmin Zhang

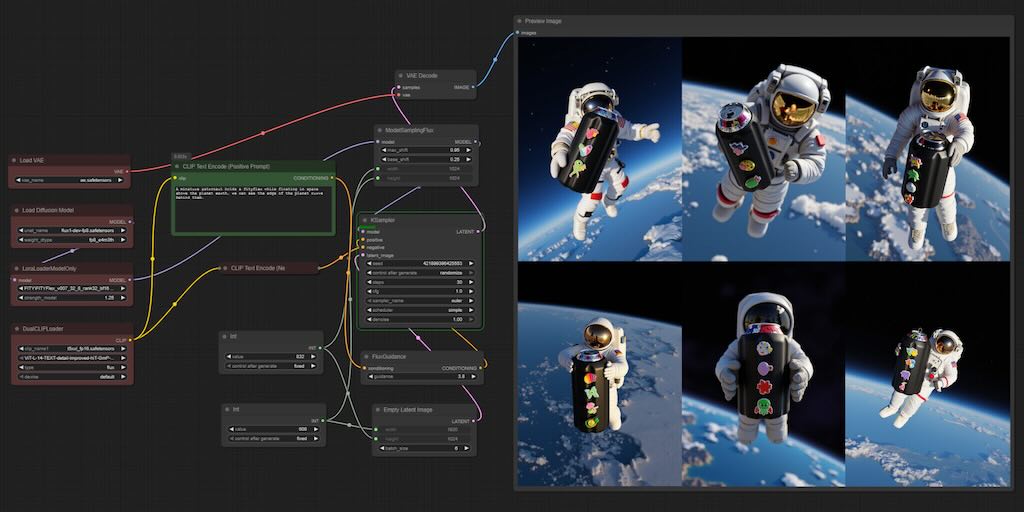
LHM (Large Animatable Human Reconstruction Model) 是一個高效及高質量的 3D 人體重建方案模型,能夠在幾秒鐘內生成影片。模型利用了多模態的 Transformer 架構,以注意力機制,對人體特徵和影像特徵進行編碼,能夠詳細保存服裝的幾何形狀和紋理。為了進一步增強細節,LHM 提出了一種針對頭部特徵的金字塔型編碼方案,能夠生成頭部區域的多種特徵。(阿里巴巴)
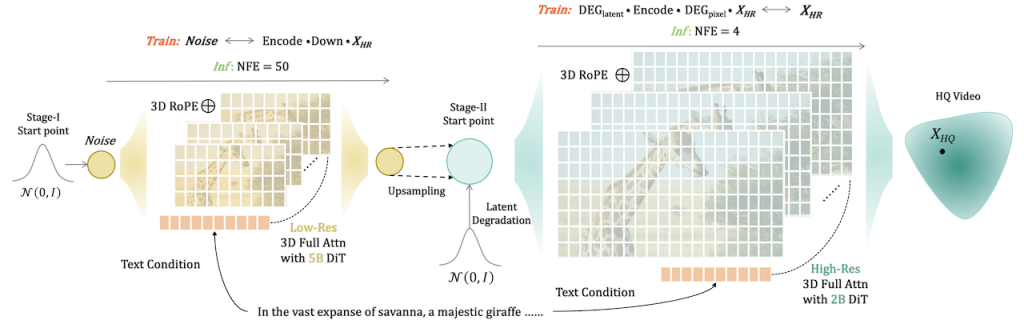
FlashVideo 由香港大學、香港科技大學及 ByteDance 聯合開發,你只需要準備一張或者幾張參考圖片,加上文字提示詞,就可以生成高解像度的影片。過程主要分為兩部份,第一部分是優先處理提示詞,同時以低解像度處理圖片,減少 DIT 的運算時間。第二部分會建立低解像度和高解像度之間的匹配。結果能夠以高速生成 1 0 8 0 P 的高清影片。[DiT] Diffusion Transformer | [NFE ] Number of Function Evaluations
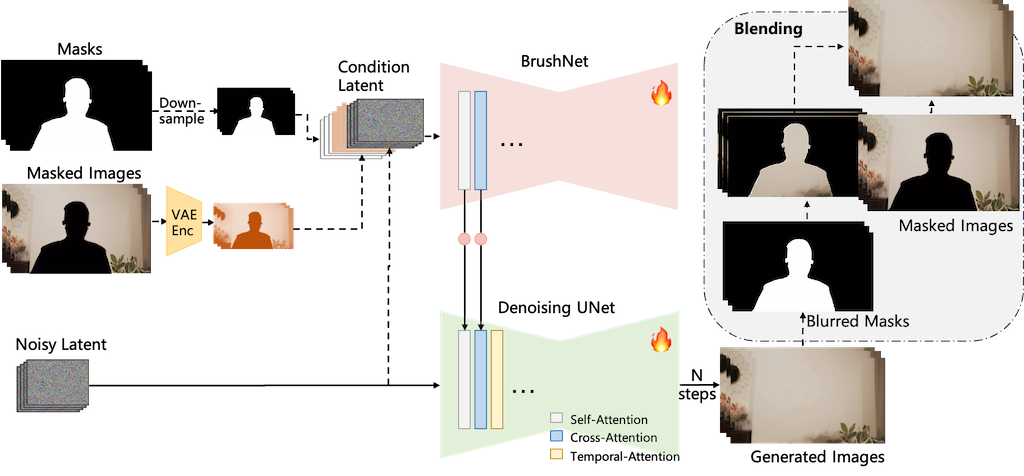
DiffuEraser 是個基於穩定擴散模型的開源影片修復模型。利用先驗資訊作為初始化,減少雜訊和幻覺,並藉由擴展時間以及利用影片擴散模型的時間平滑特性,提升長序列推論中的時間一致性。 DiffuEraser 透過結合鄰近影格資訊修復遮罩區域,展現比現有技術更佳的內容完整性和時間一致性,即使在處理複雜場景和長影片時也能產生細節豐富、結構完整且時間一致的結果,且無需文字提示。 其核心在於提升影片修復的生成能力與時間一致性。
Janus 系列多模態理解和生成模型。核心是三個模型:Janus、Janus-Pro 和 JanusFlow,它們都基於單一 Transformer 架構,實現了統一的多模態理解和生成。Janus-Pro 是 Janus 的進階版,透過優化訓練策略、擴展數據和提升模型規模,顯著提升了性能。JanusFlow 則結合了自迴歸語言模型和修正流模型,在效能和多功能性上取得平衡。該資源提供了模型下載、快速入門指南,以及使用 Python 進行多模態理解和圖像生成的程式碼範例,並提供了 Hugging Face 線上演示和本地 Gradio/FastAPI 演示的說明。 最後,還列出了相關論文的引用資訊。