https://arxiv.org/pdf/2512.24880
EP121 - DeepSeek又投震撼彈!新提出的「mHC」架構會完全改變 AI 嗎?解讀這篇 CEO 親自挂帥的論文

https://arxiv.org/pdf/2512.24880
這是 AI 領域的「秘密突破」,僅有頂尖 0.1% 的研究者知曉:直接將原始位元組(raw bytes)輸入大型語言模型(LLMs),並使用代數拓撲(algebraic topology)分析,透過持久同調(persistent homology)揭示傳統模型無法察覺的隱藏資料結構。這可能改變 AI 處理多模態資料(如文字、影像、影片)的未來。

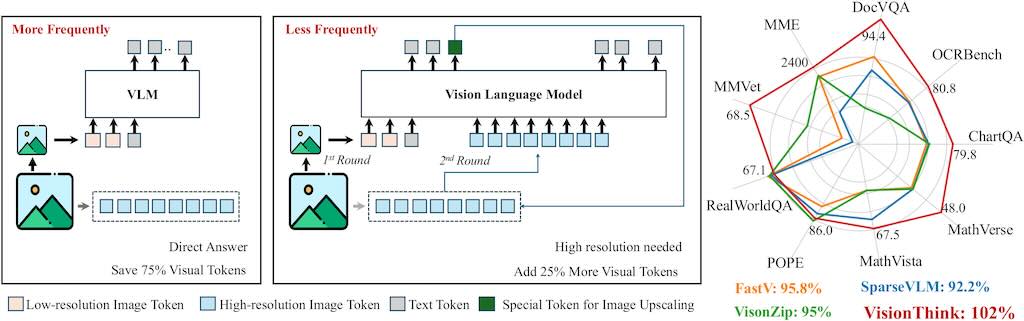
VisionThink 利用強化學習自主學習減少視覺 token。與傳統的高效 VLM 方法相比,這方法在
微粒度基準測試(例如涉及 OCR 相關任務的基準測試)上取得了顯著的提升。
由香港中文大學,香港大學,科技大學大聯合開發

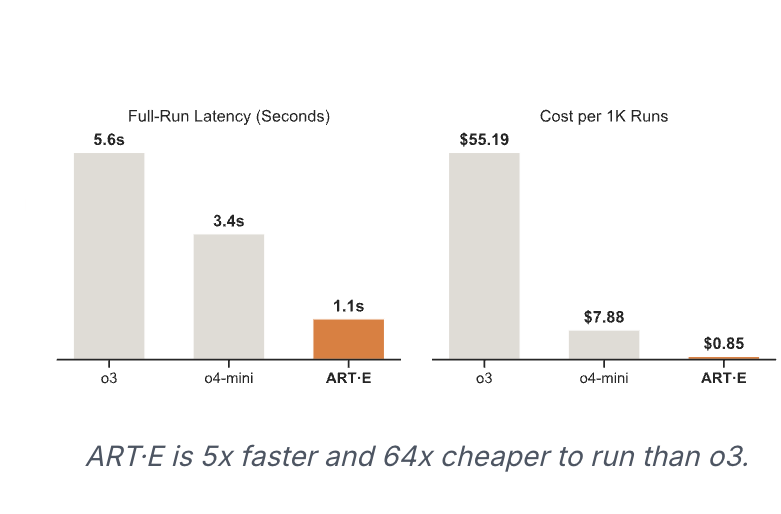
ART 是一個開源強化學習框架,它允許 LLM 從經驗中學習,從而提高代理的可靠性。 ART 提供了符合人體工學的框架,可將 GRPO 整合到任何 Python 應用程式中。
RULER(Relative Universal LLM-Elicited Rewards)透過使用 LLM-as-judge 自動評分代理軌跡,消除了手動設計獎勵函數的需要。只需在系統提示字元中定義您的任務,RULER 就會處理剩下的工作—— 無需標記資料、專家回饋或獎勵工程。
Absolute Zero 是由清華大學主導的一項創新語言模型訓練方法。這個方法最顯著的特點是不再需要由人類提供的數據進行訓練,而是自動生成問題,然後嘗試自動解決問題來進行學習。過往的監督學習,或者強化學習,一般都是由人類設定目標進行監管,而 Absolute Zero 可以透過自我對弈機制。能夠在數學和程式設計的領域中自動提升推理能力。研究顯示,這種模型不僅在這些領域達到了最先進的性能,甚至超越了由人類策劃的數據去訓練的模型。
