Page Assist 是一個瀏覽器外掛,透過 Ollama 於本機運行 AI 模型,Page Assist 提供了一個十分完善的 Ollama介面。Page Assist 強調不會收集個人資料,十分注重隱私。專案是由 MIT 授權。


Page Assist 是一個瀏覽器外掛,透過 Ollama 於本機運行 AI 模型,Page Assist 提供了一個十分完善的 Ollama介面。Page Assist 強調不會收集個人資料,十分注重隱私。專案是由 MIT 授權。
影片主要講解了如何使用冷啟動技術來提升小型語言模型(LLM)的推理能力,特別是在數學問題上的表現。影片的核心在於重現 DeepSeek R1 模型論文中提到的冷啟動方法,即透過少量高品質的合成數據集,讓模型在強化學習前就能夠生成清晰且連貫的思考鏈。這些數據集利用數學編譯器來產生精確的步驟式解題過程,並使用大型語言模型生成自然語言解釋,進而微調一個只有 15 億(1.5b)參數的小型模型,使其能夠進行複雜的數學推理,並在思考(think)和回答(answer)標籤中呈現其推理過程,而最終結果顯示即使是小型模型,也能透過冷啟動技術達到令人印象深刻的推理能力。影片也強調了冷啟動數據集的多樣性,包括數學、程式碼和其他領域,才能使模型具有強大的通用能力。

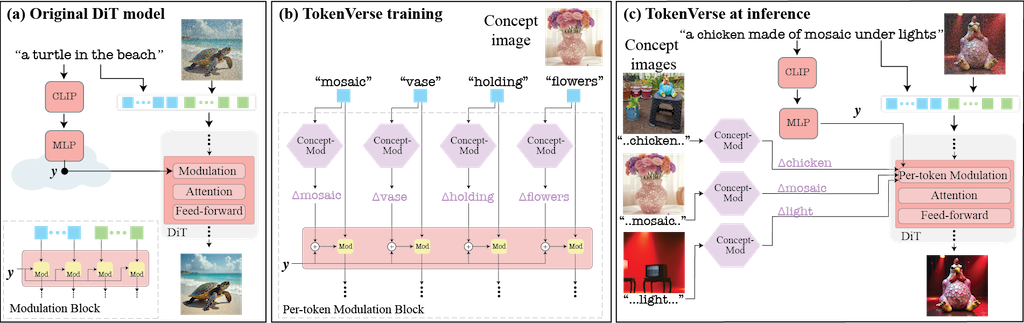
TokenVerse 提出一種基於預訓練文字轉圖像擴散模型的多概念個人化方法。它利用模型中的調製空間 (modulation space),從單張圖片中解開複雜的視覺元素和屬性,並能無縫地組合來自多張圖片的概念。不同於現有方法在概念類型或廣度上的限制,TokenVerse 能處理多張圖片的多種概念,包含物件、配件、材質、姿勢和光線等。核心方法是透過優化,為每個文字嵌入 (text embedding) 學習一個獨特的調製向量調整 (modulation vector adjustment),這些向量代表個人化的方向,可用於產生結合所需概念的新圖像。最後,論文展示了 TokenVerse 在具有挑戰性的個人化情境中的有效性,並突顯其優勢。
短片闡述 DeepSeek R1 模型的訓練過程,核心是基於人類回饋的強化學習。首先,短片解釋如何利用人類偏好訓練獎勵模型 (reward model):收集人類對不同模型輸出的評分,透過例如 Softmax 函數和梯階降法,調整獎勵模型,使其給予人類偏好的輸出更高分數。短片亦說明如何使用近端策略最佳化 (PPO) 演算法,結合獎勵模型和價值模型 (value model) 來微調語言模型 (policy network):根據獎勵模型給出的獎勵,以及評價模型預測的獎勵與預期差異 (advantage),調整策略網絡,使其更傾向產生高獎勵的輸出。最後,短片特別介紹 DeepSeek R1 使用的群體相對策略最佳化 (group relative policy optimization),這是一種改良的 PPO 方法,將獎勵與群體內其他輸出的平均獎勵相比,鼓勵產生優於平均水準的輸出,解決了傳統獎勵模型可能出現的「獎勵作弊」問題。
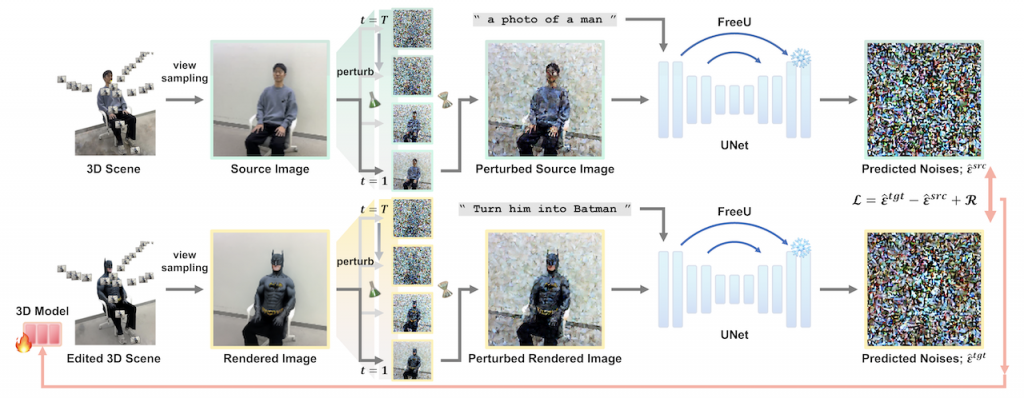
DreamCatalyst 是一個新穎的三維編輯架構,它改進了現有基於分數蒸餾採樣(SDS) 的方法,解決了訓練時間長和結果品質低的問題。DreamCatalyst 的關鍵在於將 SDS 視為三維編輯的擴散逆向過程,而不像現有方法那樣單純地蒸餾分數函數,使得更好地與擴散模型的採樣動態相協調。結果,DreamCatalyst 大幅縮短了訓練時間,並提升編輯品質,在速度和品質上都超越現有最先進的神經輻射場(NeRF) 和三維高斯散點(3DGS) 編輯方法,展現其快速且高品質的三維編輯能力。
DiffuEraser 是個基於穩定擴散模型的開源影片修復模型。利用先驗資訊作為初始化,減少雜訊和幻覺,並藉由擴展時間以及利用影片擴散模型的時間平滑特性,提升長序列推論中的時間一致性。 DiffuEraser 透過結合鄰近影格資訊修復遮罩區域,展現比現有技術更佳的內容完整性和時間一致性,即使在處理複雜場景和長影片時也能產生細節豐富、結構完整且時間一致的結果,且無需文字提示。 其核心在於提升影片修復的生成能力與時間一致性。
涵蓋 DeepSeek-R1及其衍生模型(例如R10、R1Z)的全面介紹,包含安裝設定、效能基準測試(與OpenAI模型相比),以及各種硬體環境下的除錯和最佳化方法。課程重點在於如何有效利用 DeepSeek-R1 進行文本生成和圖像處理等 AI 任務,並強調模型優化和降低運算成本的重要性,同時展望了AI模型未來的發展趨勢。

作者進行五個關於 DeepSeek R1 以及其他模型(Claude 3.5、OpenAI)的實驗。
實驗一測試模型生成 3D 瀏覽器模擬程式碼的能力,結果 DeepSeek R1 成功完成;
實驗二結合 Claude 的功能與 DeepSeek R1 的推理機制,實現更複雜的資訊處理;
實驗三探討模型在一個數值猜測遊戲中的推理過程,展現了模型的思考步驟;
實驗四修改經典的河渡問題,測試模型是否能跳脫既有訓練資料的限制,DeepSeek R1和Claude成功解決,OpenAI則失敗;
實驗五則以情境題測試模型的連續推理能力,多個模型皆能得出正確結論。
整體而言,影片旨在展示大型語言模型的程式碼生成、工具使用、推理能力以及突破訓練資料限制的潛力,並分享作者對模型能力的觀察與思考。

開源人工智慧模型 DeepSeek R1 在樹莓派上以每秒 200 個 token 的速度運作,這是個突破性進展。重點在於此模型的效能即使在資源受限的樹莓派上也能達到令人驚訝的表現,並超越某些商業模型,例如OpenAI的某些版本。文章同時比較了不同硬體平台(如樹莓派、桌上型電腦、高效能GPU)運行此模型的效能差異,並探討了其在遊戲NPC應用上的潛力,強調其離線運作、低延遲以及可定制性等優點。

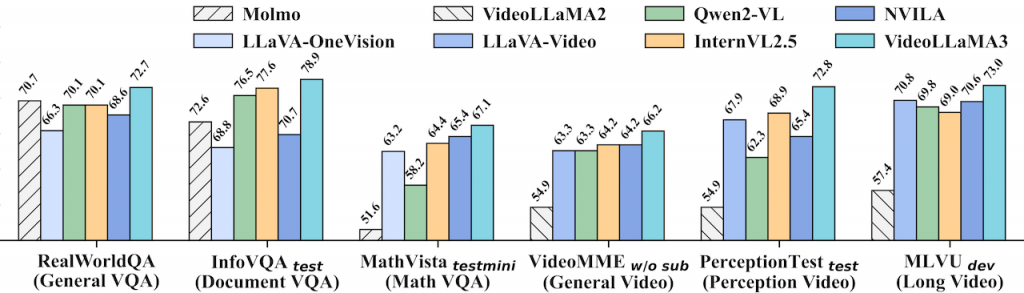
一個以視覺為中心的多模態基礎模型,用於圖像和影片理解。其核心設計理念是優先利用高品質的圖像文字數據,而非大規模的影片文字數據進行訓練。模型採用四階段訓練流程:視覺對齊、視覺語言預訓練、多任務微調以及影片中心微調。此外,VideoLLaMA3 的架構設計能根據影像大小動態調整視覺 token 數量,並在影片處理中減少冗餘的視覺 token,以提升效率和準確性。最終,VideoLLaMA3 在圖像和影片理解基準測試中取得了令人信服的成果。(HuggingFace)