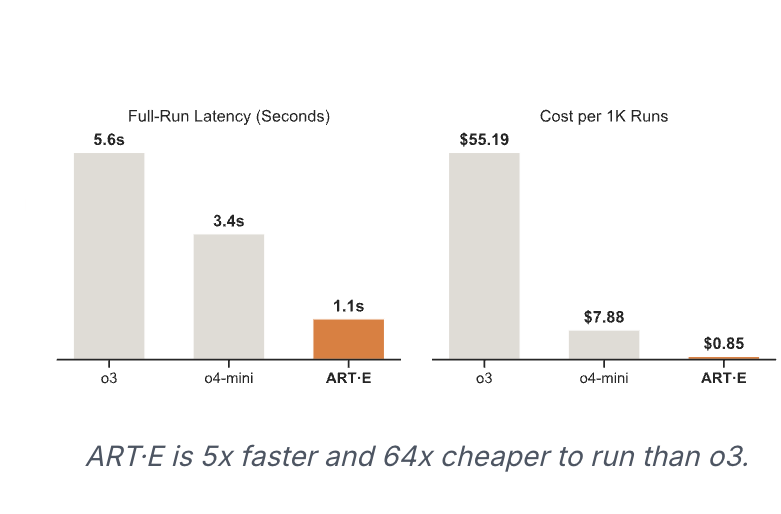
3AM 是一種結合了 2D 即時分割模型 SAM2 與 3D 幾何資訊的方法,目的是在影片或任意多視角圖像集合中,對同一物體保持一致的分割 mask。傳統的 2D 追蹤模型(如 SAM2)在觀點大幅變化時會因為只能依賴外觀特徵而失去目標,而早期的 3D 方法則需要提供相機位姿、深度圖或複雜的前處理,才能保證跨視角的一致性。
3AM 的創新在於在模型訓練階段,透過輕量的特徵合併模組把從 MUSt3R(一個多視角重建模型)學到的隱式幾何特徵與 SAM2 的外觀特徵結合,形成既能捕捉空間位置又能反映視覺相似度的表示。這樣的融合讓模型在推論時只需要原始 RGB 影像和使用者提供的提示(點、框、mask 等),就能在不同觀點之間追蹤物體,且不需要額外的相機資訊或前處理步驟。文章指出,這種做法在包含大量視角變化的基準測試集(如 ScanNet++、Replica)上,IoU 數值提升顯著,例如在 ScanNet++ 的 Selected Subset 上比 SAM2Long 高出約 15.9 個百分點。整體而言,3AM 在保持即時、可提示化的特性同時提升了跨視角的一致性,為後續的 3D 實例分割與多視角物體追蹤提供了一個更簡單、更有效的解方案。